- Overview
- Getting Started Guide
- UserGuide
-
References
-
ABEJA Platform CLI
- CONFIG COMMAND
- DATALAKE COMMAND
- DATASET COMMAND
- TRAINING COMMAND
-
MODEL COMMAND
- check-endpoint-image
- check-endpoint-json
- create-deployment
- create-endpoint
- create-model
- create-service
- create-trigger
- create-version
- delete-deployment
- delete-endpoint
- delete-model
- delete-service
- delete-version
- describe-deployments
- describe-endpoints
- describe-models
- describe-service-logs
- describe-services
- describe-versions
- download-versions
- run-local
- run-local-server
- start-service
- stop-service
- submit-run
- update-endpoint
- startapp command
- SECRET COMMAND
- SECRET VERSION COMMAND
-
ABEJA Platform CLI
- FAQ
- Appendix
Function of ABEJA Platform
Introduction
This page explains the functions of ABEJA Platform. ABEJA Platform provides functions for each task required for machine learning.
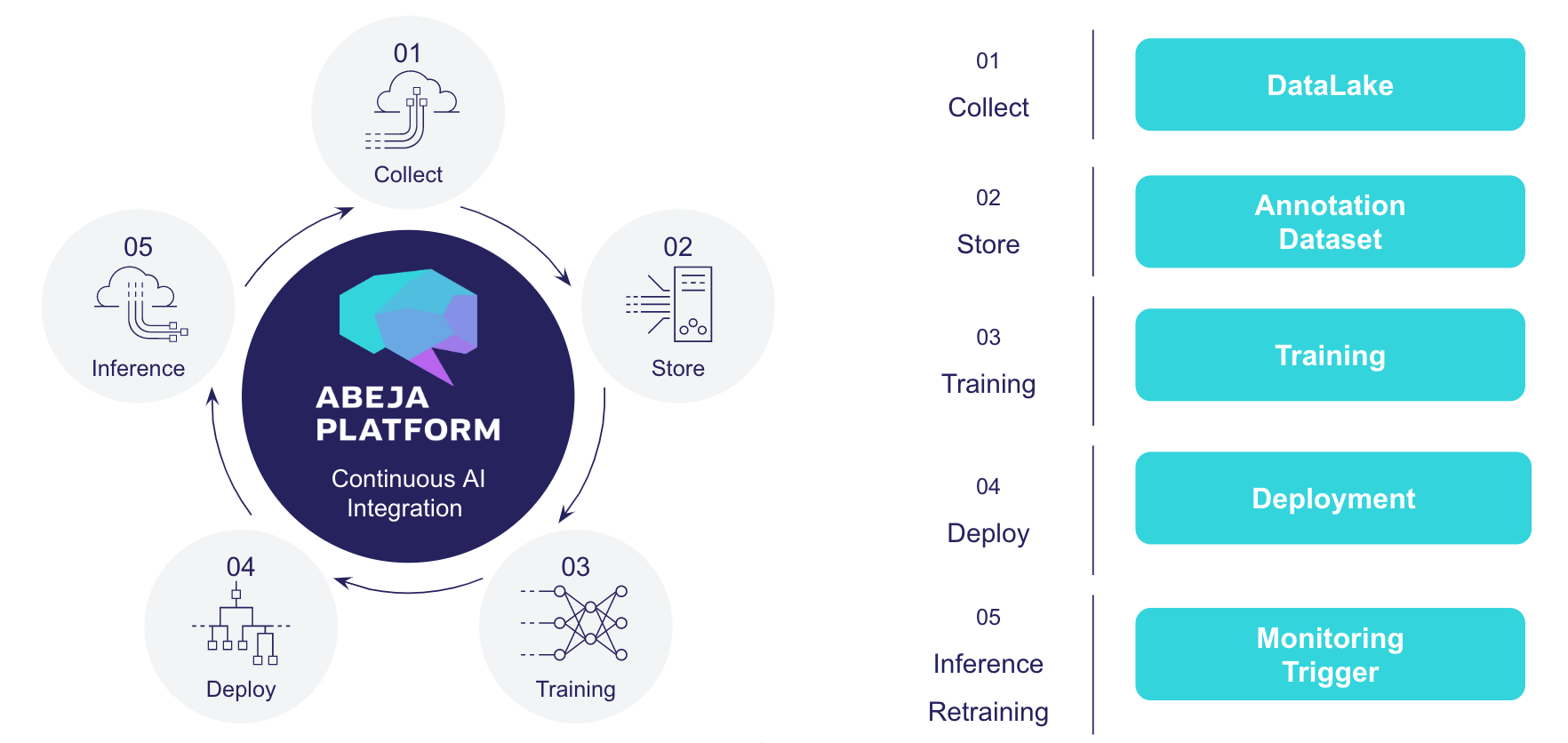
DataLake
- Features for storing and retrieving data
- Data source function allows data input / output via API
- Cooperation with annotation tool. Create supervised data efficiently
Annotation
- GUI can be used to selecting templates, set labels, and export to datasets
- Supports repetitive templates such as images, audio, video, and text
- With the review function, work can be shared by roles such as workers and reviewers
- Supports pre-inference function
Dataset
- Manage raw data and annotated data uploaded to the datalake
- You can also save your own annotated data
Training
- You can be collectively managed with GUI (Training job, Parameters, and Accuracy results, etc.)
- Various frameworks can be used
- Jyupyter Notebook
- Local Training features
- Template features
Model / Deploy
- Model version control
- Web API Deployment
- Deploy multiple versions of the API
- Blue/Green Deployment
- Edge Device Deployment
Monitoring / Trigger
- Training log / Web API log
- API monitoring with metrics
- Cooperation with input data by trigger function