- Overview
- Getting Started Guide
- UserGuide
-
References
-
ABEJA Platform CLI
- CONFIG COMMAND
- DATALAKE COMMAND
- DATASET COMMAND
- TRAINING COMMAND
-
MODEL COMMAND
- check-endpoint-image
- check-endpoint-json
- create-deployment
- create-endpoint
- create-model
- create-service
- create-trigger
- create-version
- delete-deployment
- delete-endpoint
- delete-model
- delete-service
- delete-version
- describe-deployments
- describe-endpoints
- describe-models
- describe-service-logs
- describe-services
- describe-versions
- download-versions
- run-local
- run-local-server
- start-service
- stop-service
- submit-run
- update-endpoint
- startapp command
- SECRET COMMAND
- SECRET VERSION COMMAND
-
ABEJA Platform CLI
- FAQ
- Appendix
Train model
Introduction
This page introduces the training of models using the created data set in ABEJA Platform.
First, download the source code used in this tutorial.
Train the model
Use of annotation tool created a dataset by annotating the accumulated images. Use that dataset to retrain the model.
Create a learning job definition
Click “Training” > “Job Definition” in the left menu.
Click “Create Job Definition” at the top right of the screen.
Enter a learning job definition name in the input form and create a learning job definition. The learning job definition name must be composed of alphanumeric characters or _. For example, “fashion_classification”.
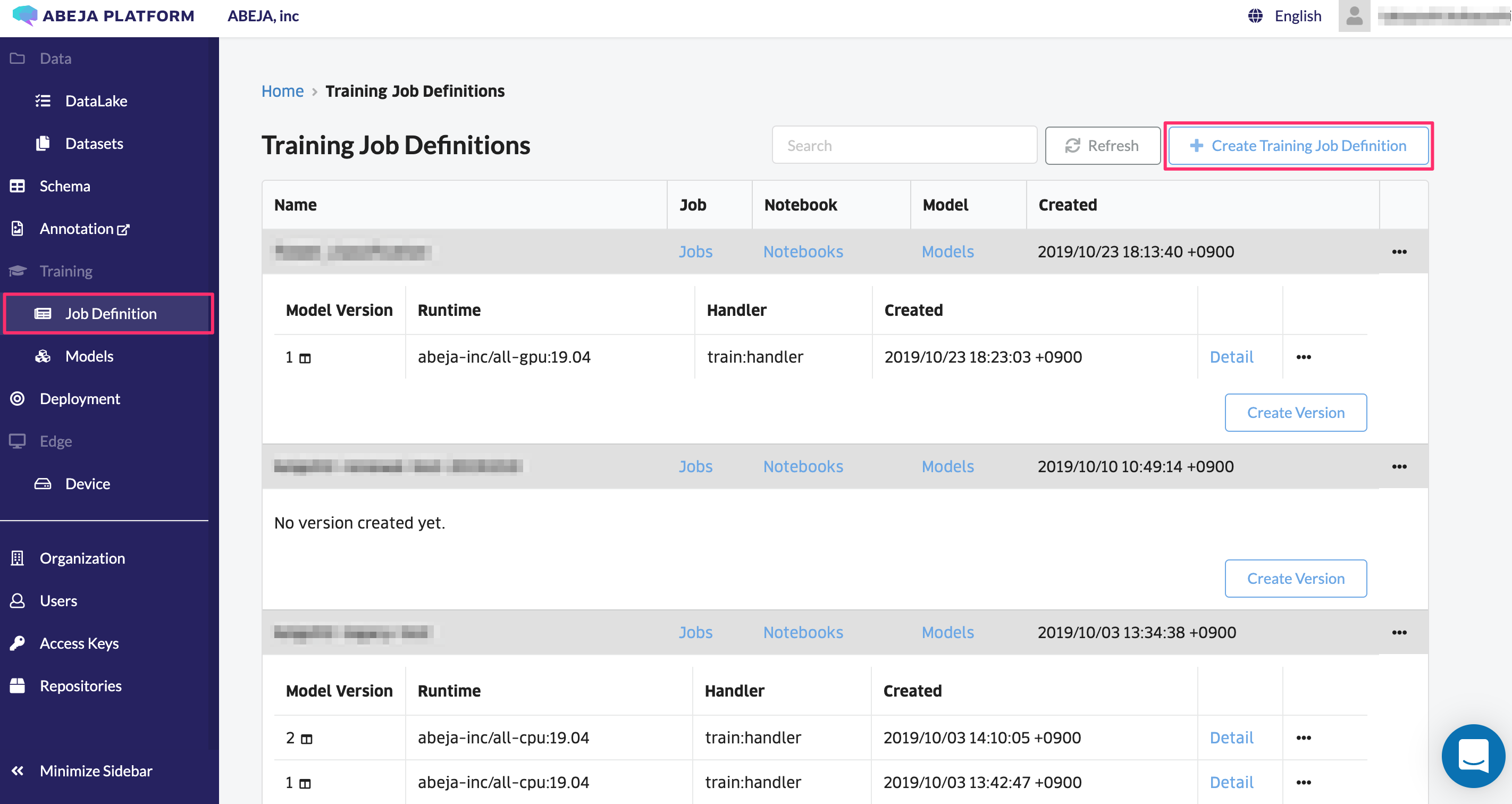
If the creation is successful, the following screen is displayed.
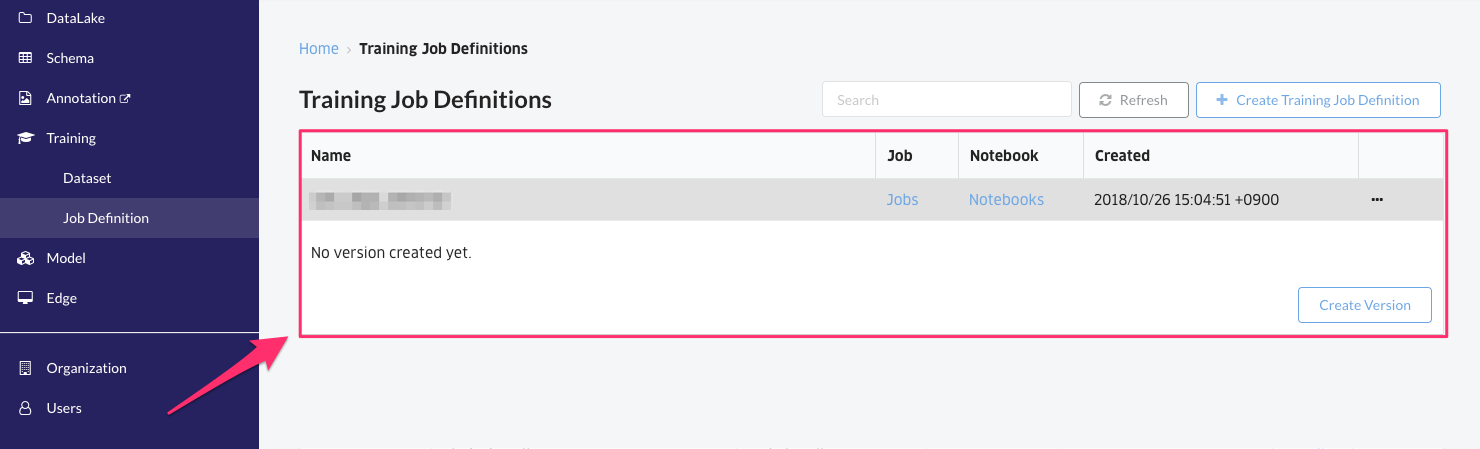
Create a version of the training job definition
Create a version of the training job definition. One version of the learning job definition consists of a combination of “ 1) Dataset used for learning ” and “ 2) Learning code “.
Click “Create version” on the created learning job definition screen to create a version of the learning job definition.
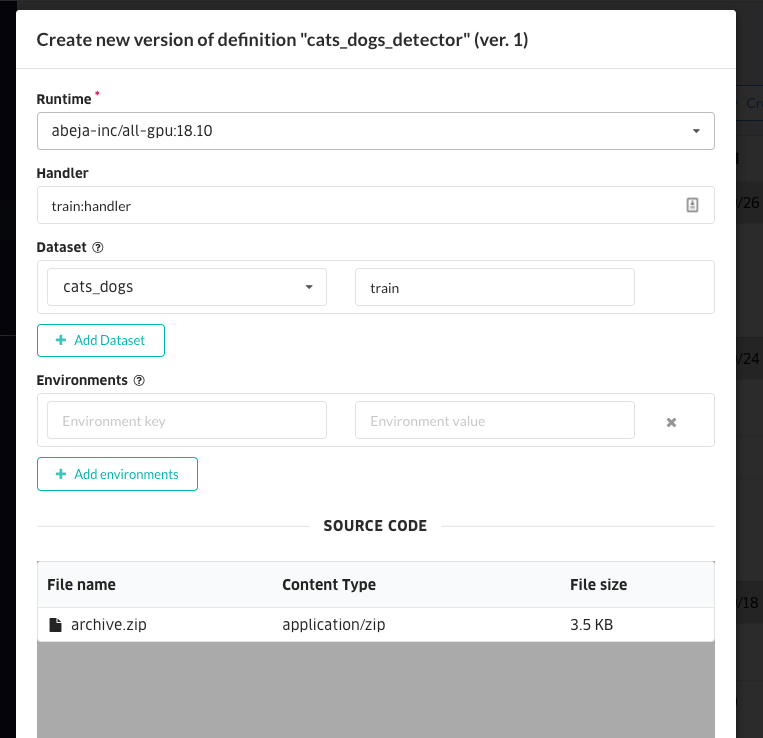
Enter the information used for learning, and create a learning job definition version.
| Item | Value |
|---|---|
| Runtime | abeja-inc/all-gpu:19.04 |
| Handler | train:handler |
| Datasets | fashion_classification |
| Datasets alias | train |
| Source Code | Upload the downloaded zip file |
Run a training job
Click “Jobs” on the learning job definition screen to move to the learning job list screen.
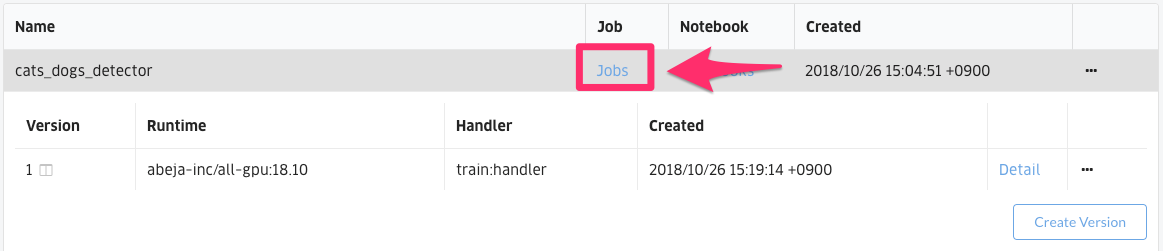
Click “Create Training Job” in the upper right of the screen after moving.
Select the training job definition version you created earlier (the first version is 1) and click” Create Training Job “.
A training job has started.
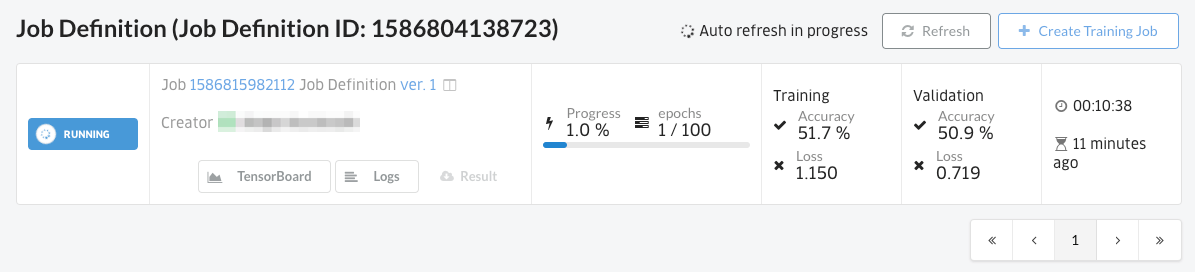
You can also check the learning code log by clicking the “Logs” button.
Validation data is a data set prepared separately from the training data to verify the accuracy of the learned model. Since machine learning is optimized for learning data, good accuracy is obtained for learning data. However, the accuracy of actual data that is not used for learning is important, so validation data is used for verification. In this sample, the data set is separated into learning data and validation data when the learning code is executed.
Confirm the completion of the training job
When the status is “Success”, it is complete.

Machine learning model version management
By improving the learning code and improving the quantity and quality of the learning data set, you can create a more accurate model. Version control of these combinations enables continuous model improvement.
Create model the created learning result is created as a model. Switch Web API Add a new model version with the trained model created this time, deploy that version as WebAPI, and then switch to the currently used WebAPI.