- 概要
- スタートアップガイド
- ユーザガイド
-
リファレンス
-
ABEJA Platform CLI
- CONFIG COMMAND
- DATALAKE COMMAND
- DATASET COMMAND
- TRAINING COMMAND
-
MODEL COMMAND
- check-endpoint-image
- check-endpoint-json
- create-deployment
- create-endpoint
- create-model
- create-service
- create-trigger
- create-version
- delete-deployment
- delete-endpoint
- delete-model
- delete-service
- delete-version
- describe-deployments
- describe-endpoints
- describe-models
- describe-service-logs
- describe-services
- describe-versions
- download-versions
- run-local
- run-local-server
- start-service
- stop-service
- submit-run
- update-endpoint
- startapp command
- SECRET COMMAND
- SECRET VERSION COMMAND
-
ABEJA Platform CLI
- FAQ
- Appendix
ワークを作成する
ワークとは
ワークは単一のデータソース(GCSやS3のフォルダ,データレイクなど)に紐づけて作成されるプロジェクト内の管理単位です。
個別にタスクのインポートが行えるため、プロジェクト内でタスクをグループ化して管理することができます。
また、個別にアノテーターをアサインすることができるため、権限範囲の管理のためにも使うことができます。
1つのプロジェクトに対して複数のワークを作成できます。
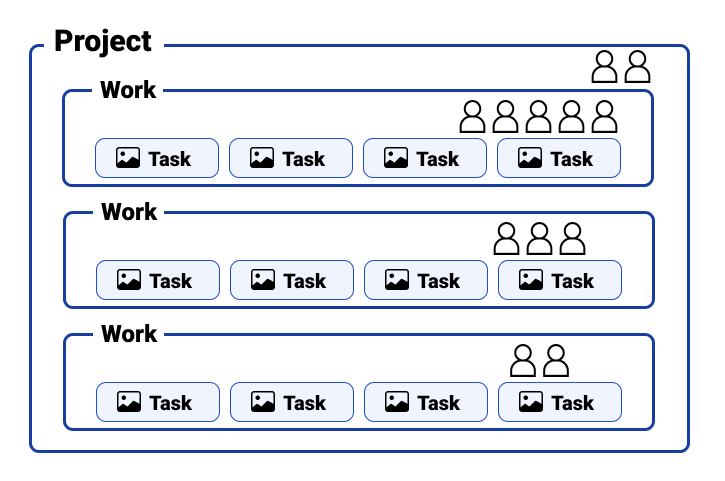
ワークごとに作業者のアサイン、対象データの追加、結果の出力ができます。 また、プロジェクトにアサインされた作業者はプロジェクト配下の全てのワークに自動的にアサインされます。
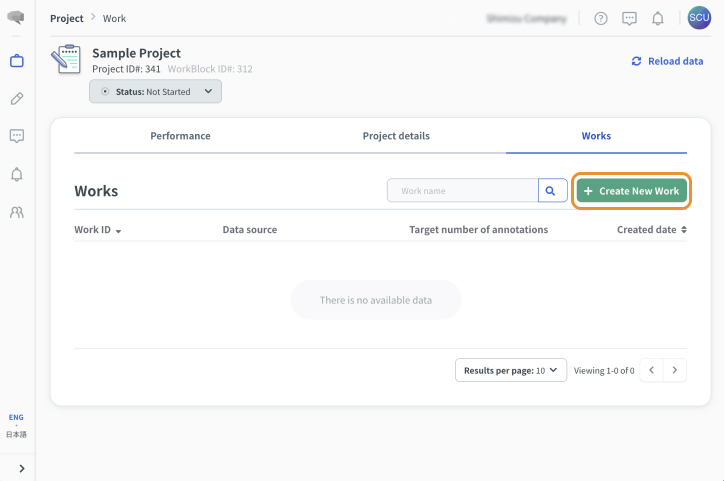
ワーク作成画面を開く
ワーク作成画面を表示します。
- ワークを作成したいプロジェクトを選択します。
- プロジェクトページの「ワーク」タブを選択します。
- 「新規ワーク作成」を選択します。
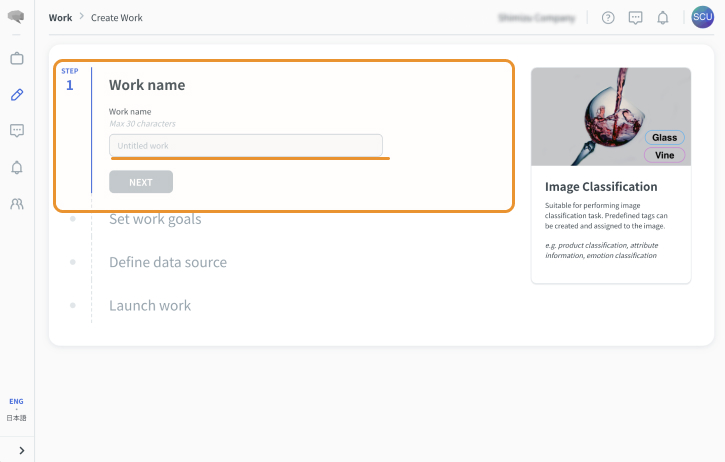
ワーク名を設定する
任意のワーク名を入力して次へを選択します。
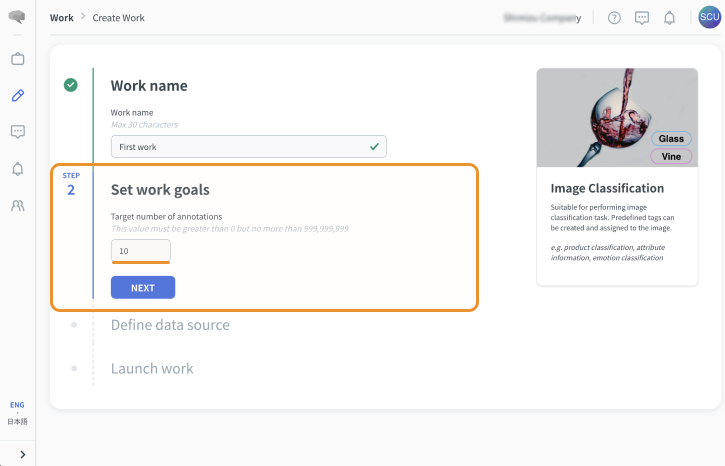
完了条件を設定する
アノテーション作業の目標数を設定します。
データを添付する
アノテーションを行いたいデータを選択します。
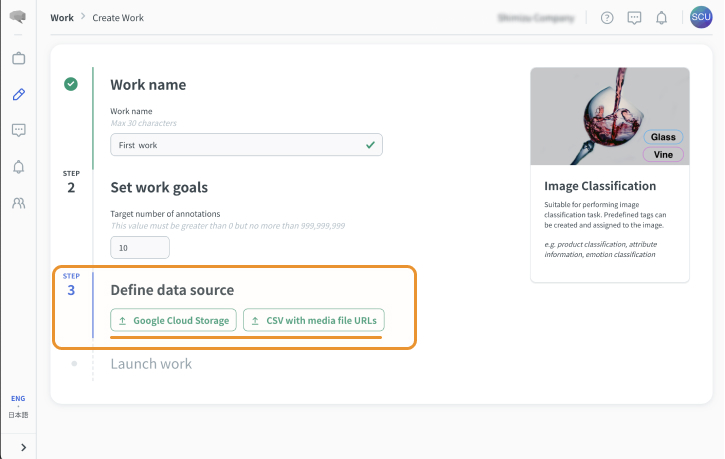
A:Google Cloud Storage または AWS S3 にデータがある場合
- プロジェクトで指定したバケット配下のデータが格納されたディレクトリ名を入力します。
- API経由でタスクを作成する場合はチェックボックスを有効にします。(APIを利用する場合、インポート機能は利用できなくなります)
- 次へを選択します。

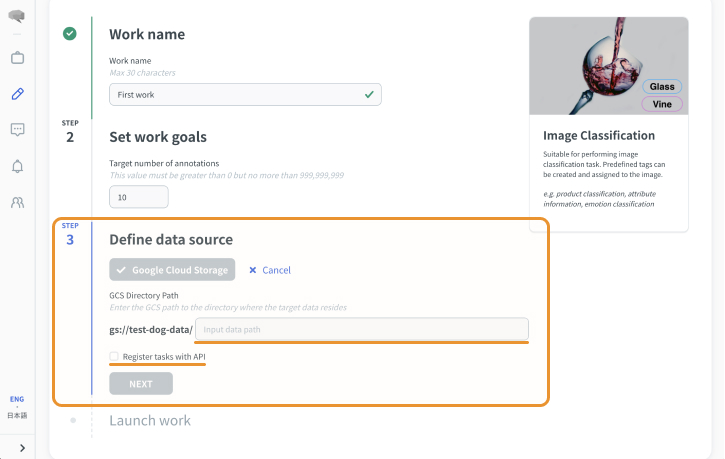
B:CSVを利用する場合
- 次へを選択します。
「CSVを利用する」をご確認ください。
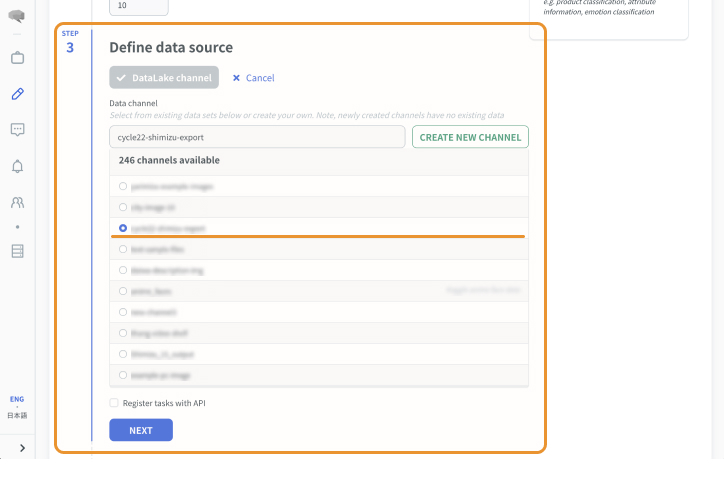
C:データレイクを利用する場合
- データレイクチャンネルを選択します。
- 利用可能チャンネルの一覧から、アノテーション対象を選択します。
- API経由でタスクを作成する場合はチェックボックスを有効にします。(APIを利用する場合、インポート機能は利用できなくなります)
- 次へを選択します。
新規にデータレイクのチャネルを作成してファイルをアップロードする場合は 「データをアップロードする」をご確認ください。
作成する
「ワークを保存して作成する」を選択します。
APIを利用しない場合、「作成後すぐにタスクの生成を開始する」を有効にすると、自動的にデータの読み込みが開始されます。
