- 概要
- スタートアップガイド
- ユーザガイド
-
リファレンス
-
ABEJA Platform CLI
- CONFIG COMMAND
- DATALAKE COMMAND
- DATASET COMMAND
- TRAINING COMMAND
-
MODEL COMMAND
- check-endpoint-image
- check-endpoint-json
- create-deployment
- create-endpoint
- create-model
- create-service
- create-trigger
- create-version
- delete-deployment
- delete-endpoint
- delete-model
- delete-service
- delete-version
- describe-deployments
- describe-endpoints
- describe-models
- describe-service-logs
- describe-services
- describe-versions
- download-versions
- run-local
- run-local-server
- start-service
- stop-service
- submit-run
- update-endpoint
- startapp command
- SECRET COMMAND
- SECRET VERSION COMMAND
-
ABEJA Platform CLI
- FAQ
- Appendix
モデルの学習
はじめに
本ドキュメントを通じて、 ABEJA Platform の GUI を利用して、 作成したデータセットを学習データとしてモデルの学習を行います。
まずは今回のチュートリアルで使うソースコードをダウンロードしてください。
モデルの学習を行う
前回までで蓄積した画像にアノテーションを行い、新たにデータセットを作成しました。 ここでは、そのデータセットを使用して、モデルの再学習を行います。
学習ジョブ定義を作成する
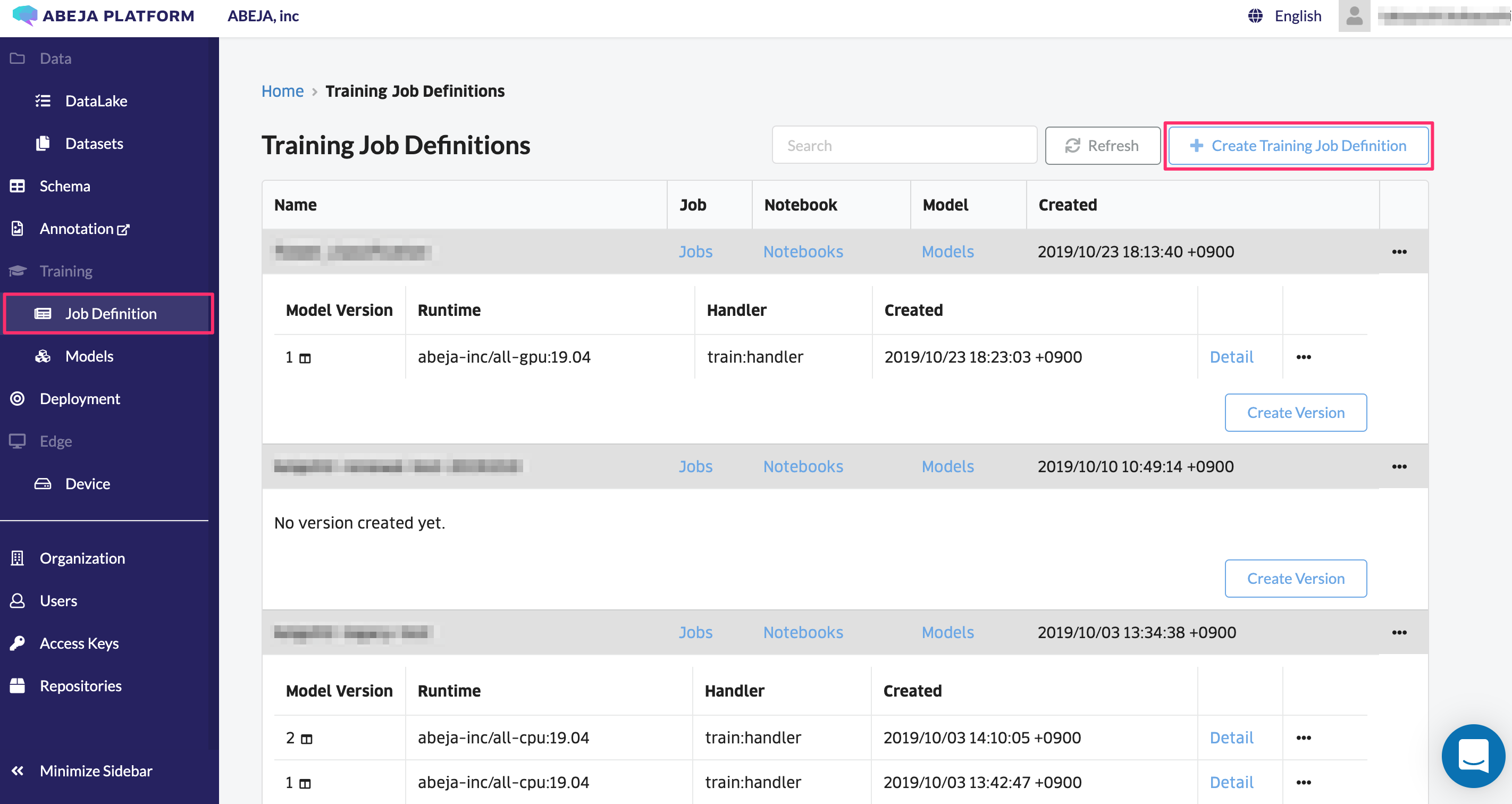
左部メニューの “Training > Job Definition” をクリックします。
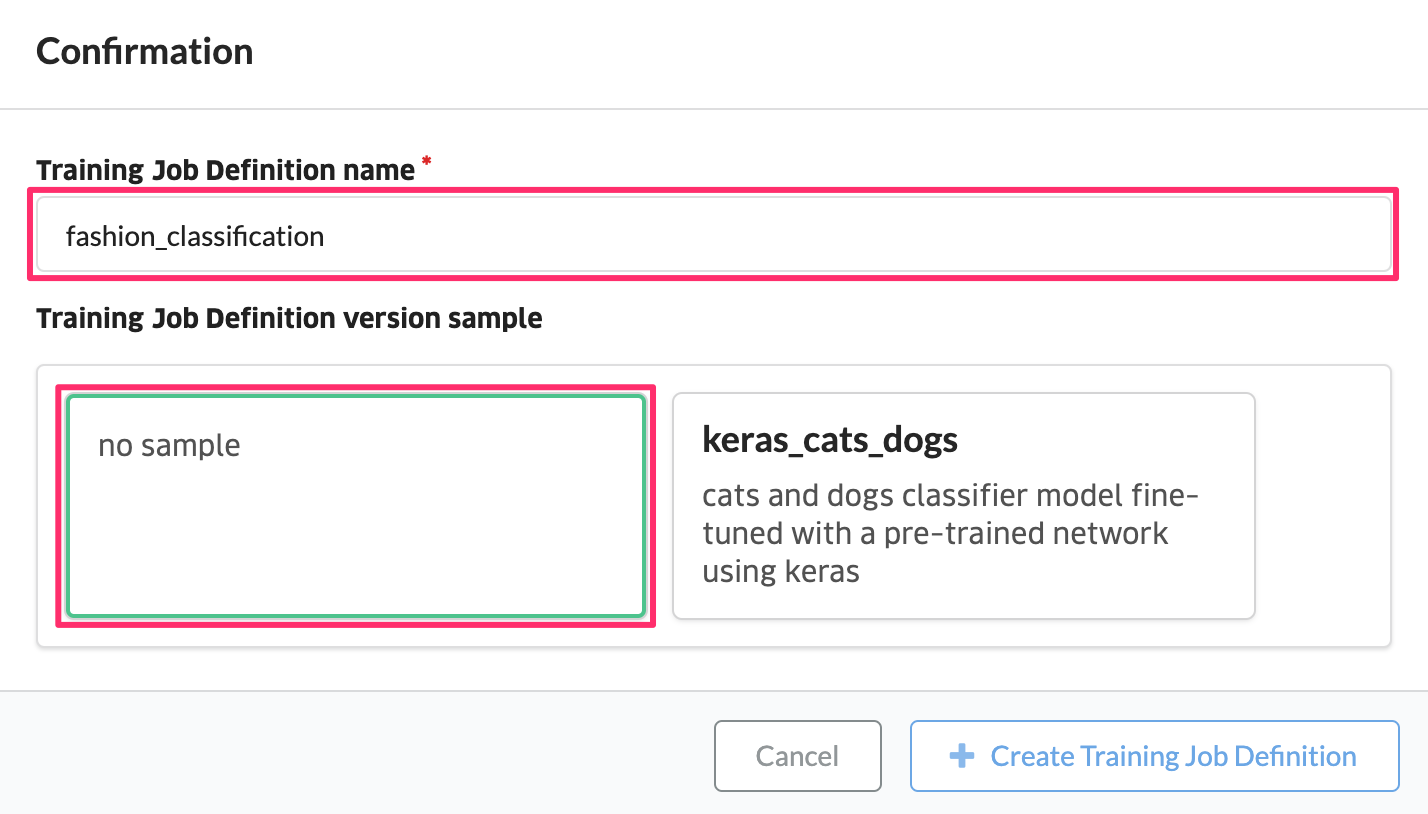
画面右上の “Create Job Definition” をクリックします。入力フォームに学習ジョブ定義名を入力し、学習ジョブ定義を作成します。学習ジョブ定義名は「英数字または _」で構成された名前にします。たとえば、”fashion_classification” としてください。
学習ジョブ定義のバージョンを作成する
学習ジョブ定義のバージョンを作成します。学習ジョブ定義のひとつのバージョンは「1) 学習に利用するデータセット」「2) 学習用のコード」の組み合わせによって構成されます。
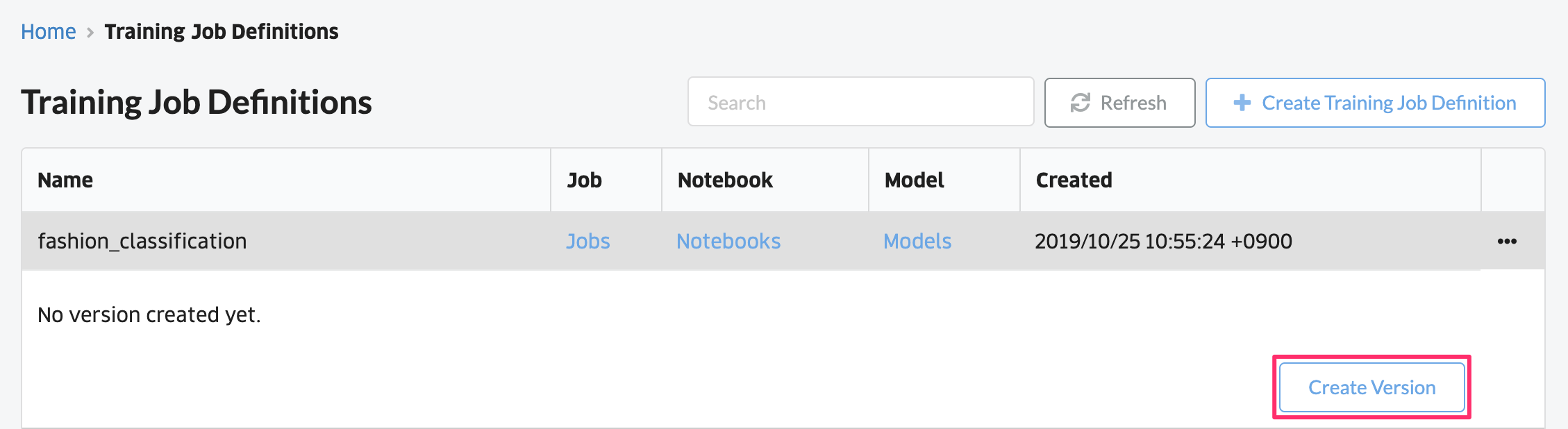
先ほど作成した学習ジョブ定義画面の ”Create version” をクリックして、学習ジョブ定義のバージョンを作成します。
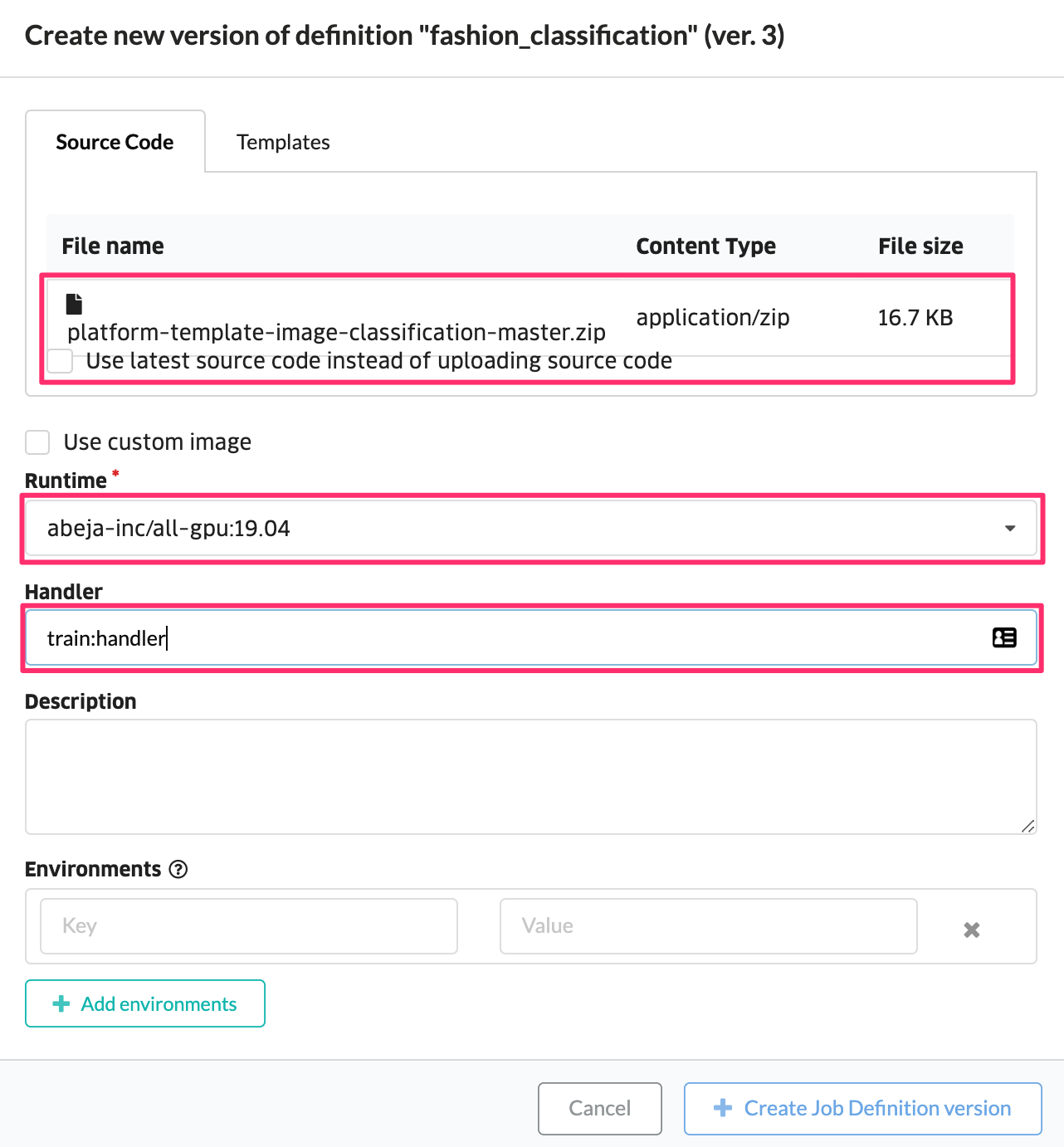
学習に利用する情報を入力し、学習ジョブ定義バージョンを作成して下さい。
| 項目 | 値 |
|---|---|
| Runtime | abeja-inc/all-gpu:19.04 |
| Handler | train:handler |
| Source Code | 先ほどダウンロードしたzipファイルをアップロードする |
学習ジョブを実行する
学習ジョブ定義画面の “Jobs” をクリックし、学習ジョブ一覧画面に移動します。
移動後の画面の右上、 “Create Training Job” をクリックします。先ほど作成した学習ジョブ定義バージョン(最初のバージョンなので、1)を選択し、 “Create Training Job” をクリックします。

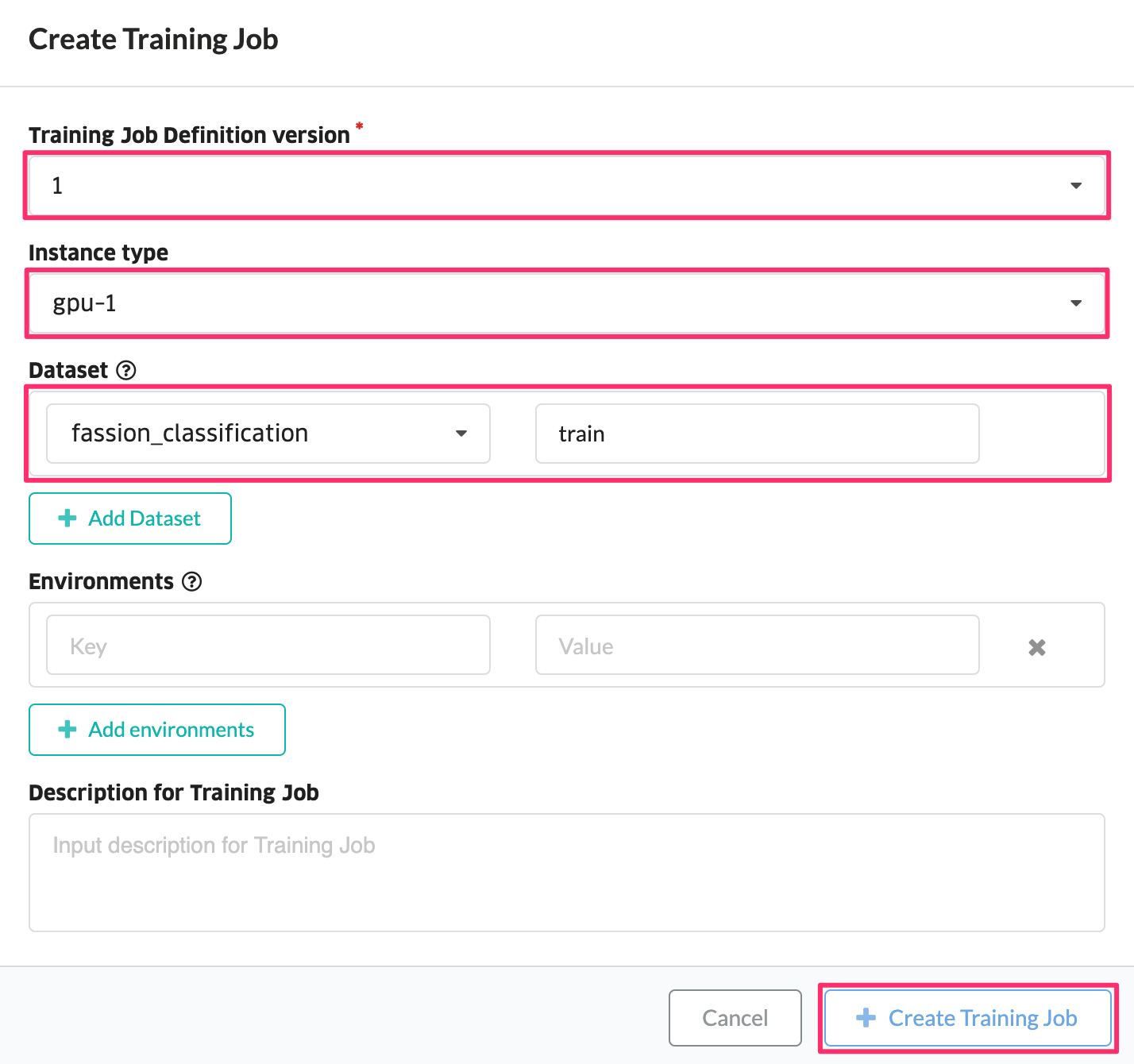
学習ジョブに利用する情報を入力し、学習ジョブを作成して下さい。
| 項目 | 値 |
|---|---|
| Training Job Definition version | 1 |
| Instance type | gpu-1 |
| Dataset | fashion_classification |
| Dataset alias | train |
学習ジョブが開始されました。
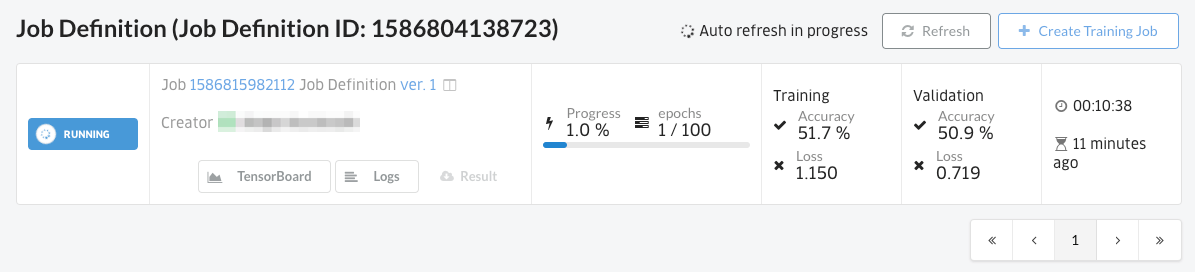
“Logs”ボタンをクリックし、学習コードのログを確認することも出来ます。
バリデーションデータは、学習したモデルの精度を検証するための、学習データとは別に用意したデータセットです。機械学習は学習データに対して最適化しているので、学習データに対しては良い精度は出ます。しかし、学習に使わなかった、実際のデータに対する精度が重要になるので、バリデーションデータを使って検証します。 本ドキュメントのサンプルでは、学習コードの実行時にデータセットを学習データと、バリデーションデータに分離して利用しています。
学習ジョブの完了を確認する
ステータスが”Success”になると完了です。

機械学習モデルのバージョン管理
学習用コードの改善や、学習用データセットの量と質を向上させる事で、より精度の高いモデルを手に入れる事ができます。 これらの組み合わせをバージョン管理することで、継続的にモデルの改善が可能です。
モデルの登録では、作成した学習結果をモデルとして作成します。 Web API の切り替えでは、今回作成した学習済みモデルで新たにモデルバージョンを追加して、そのバージョンを WebAPI としてデプロイした後に、現在使用されている WebAPI と切り替えます。