- 概要
- スタートアップガイド
- ユーザガイド
-
リファレンス
-
ABEJA Platform CLI
- CONFIG COMMAND
- DATALAKE COMMAND
- DATASET COMMAND
- TRAINING COMMAND
-
MODEL COMMAND
- check-endpoint-image
- check-endpoint-json
- create-deployment
- create-endpoint
- create-model
- create-service
- create-trigger
- create-version
- delete-deployment
- delete-endpoint
- delete-model
- delete-service
- delete-version
- describe-deployments
- describe-endpoints
- describe-models
- describe-service-logs
- describe-services
- describe-versions
- download-versions
- run-local
- run-local-server
- start-service
- stop-service
- submit-run
- update-endpoint
- startapp command
- SECRET COMMAND
- SECRET VERSION COMMAND
-
ABEJA Platform CLI
- FAQ
- Appendix
学習・モデル作成
はじめに
このドキュメントでは、「データ取得・データセット作成」で作成したデータセットを利用し、ABEJA Templateを利用して、ノンコーディングで機械学習モデル作成を解説します。
ステップ1 学習データを用意する
学習データはデータ取得・データセット作成を実施後を想定しております。
もし、個別で学習データを利用したい場合、以下のドキュメントをご参考の上、学習データを用意ください。
■データレイクへファイルをアップロードし、アノテーションツールを使ってデータセットを作成する
■アノテーション済みのデータを既にお持ちの場合
ステップ2 データを使って学習する
学習データを元にABEJA Template を利用して機械学習モデルを作成します。今回はImage Classificationのタスクを用います。 まずは、コンソールの学習のジョブ定義のページから、ジョブ定義を作成します。
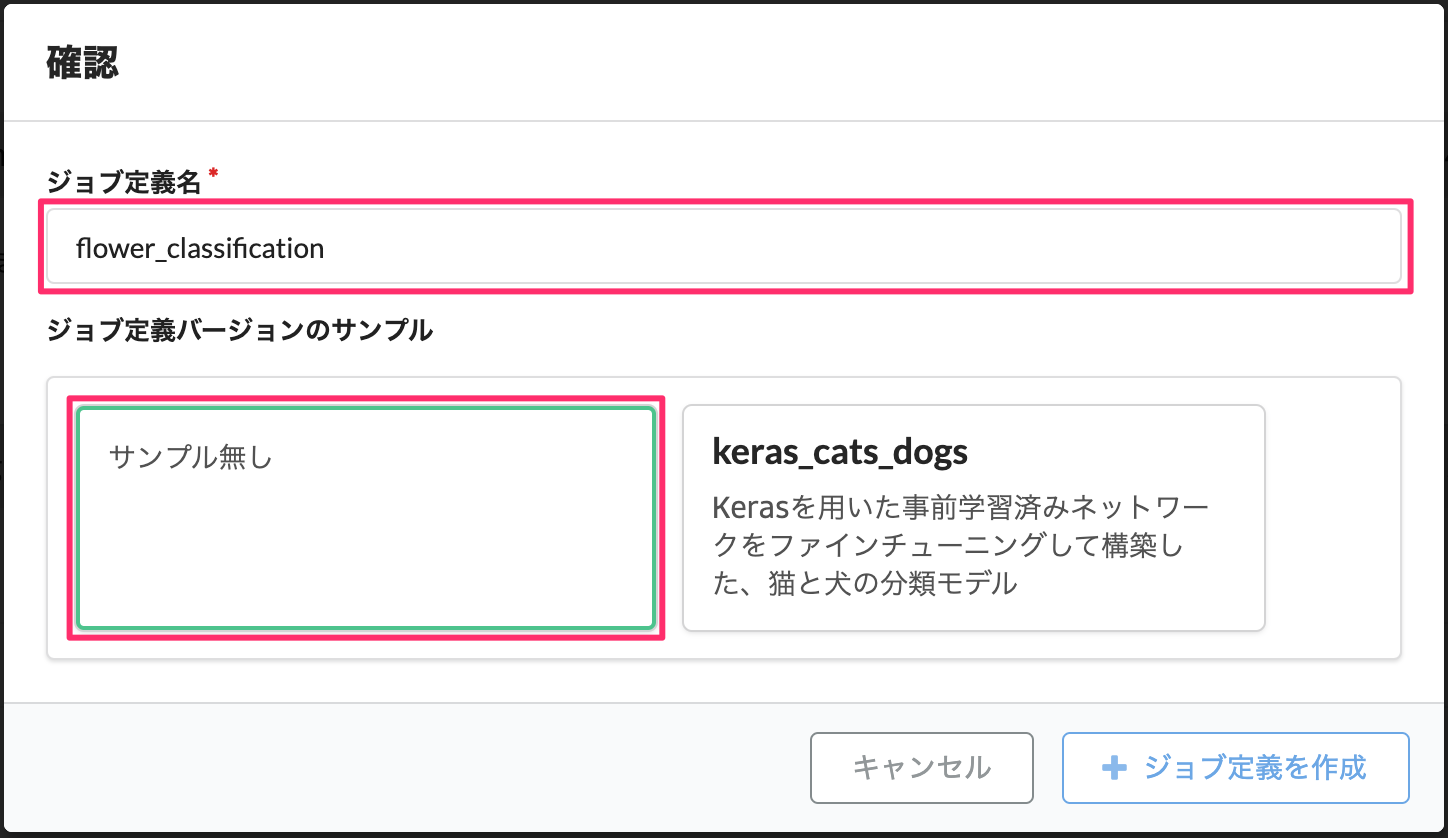
ジョブ定義名を入力し、「サンプル無し」を選択します。
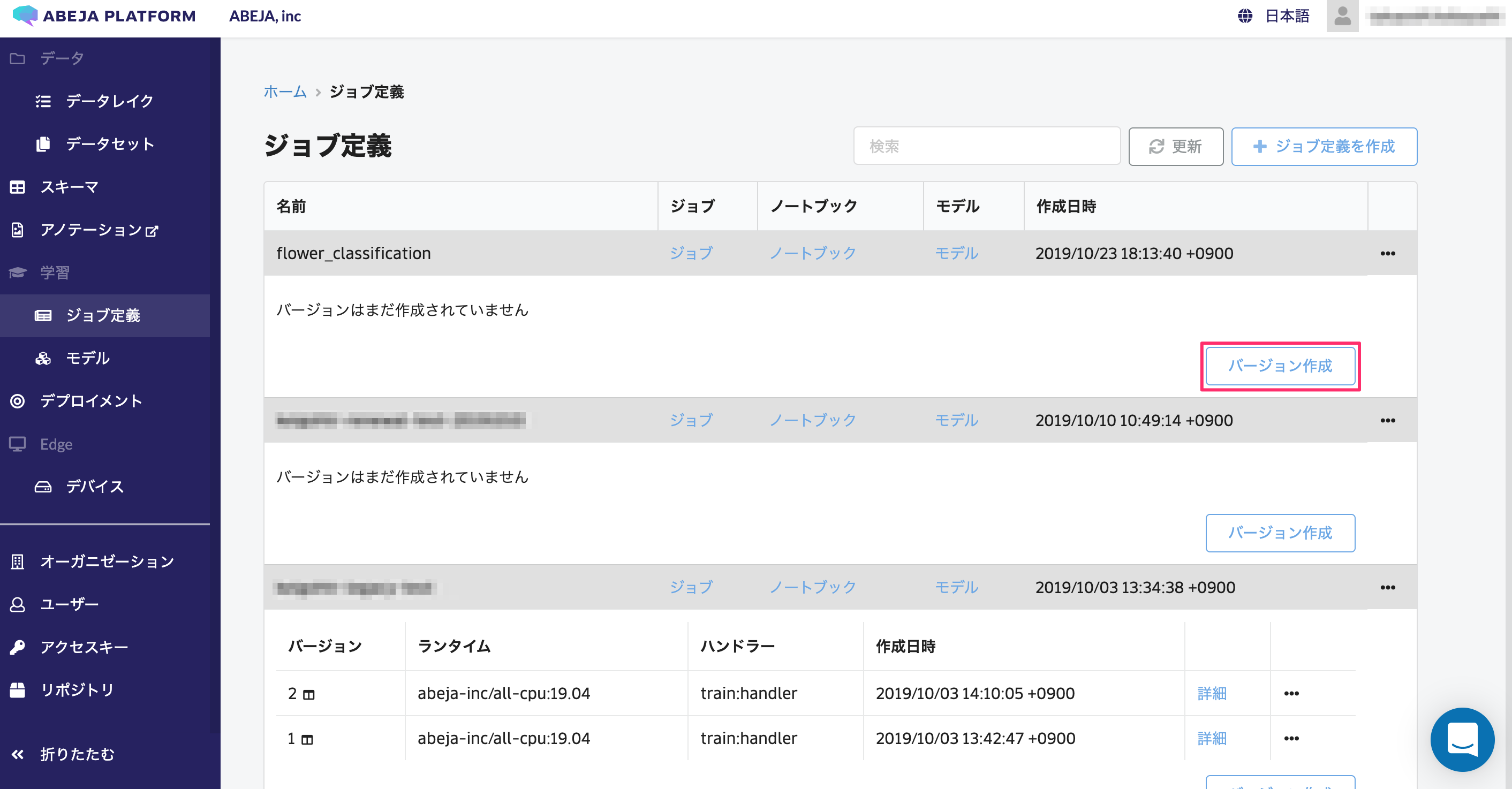
その後、バージョンを作成します。先程、作成したジョブ定義から「バージョン作成」を選択します。
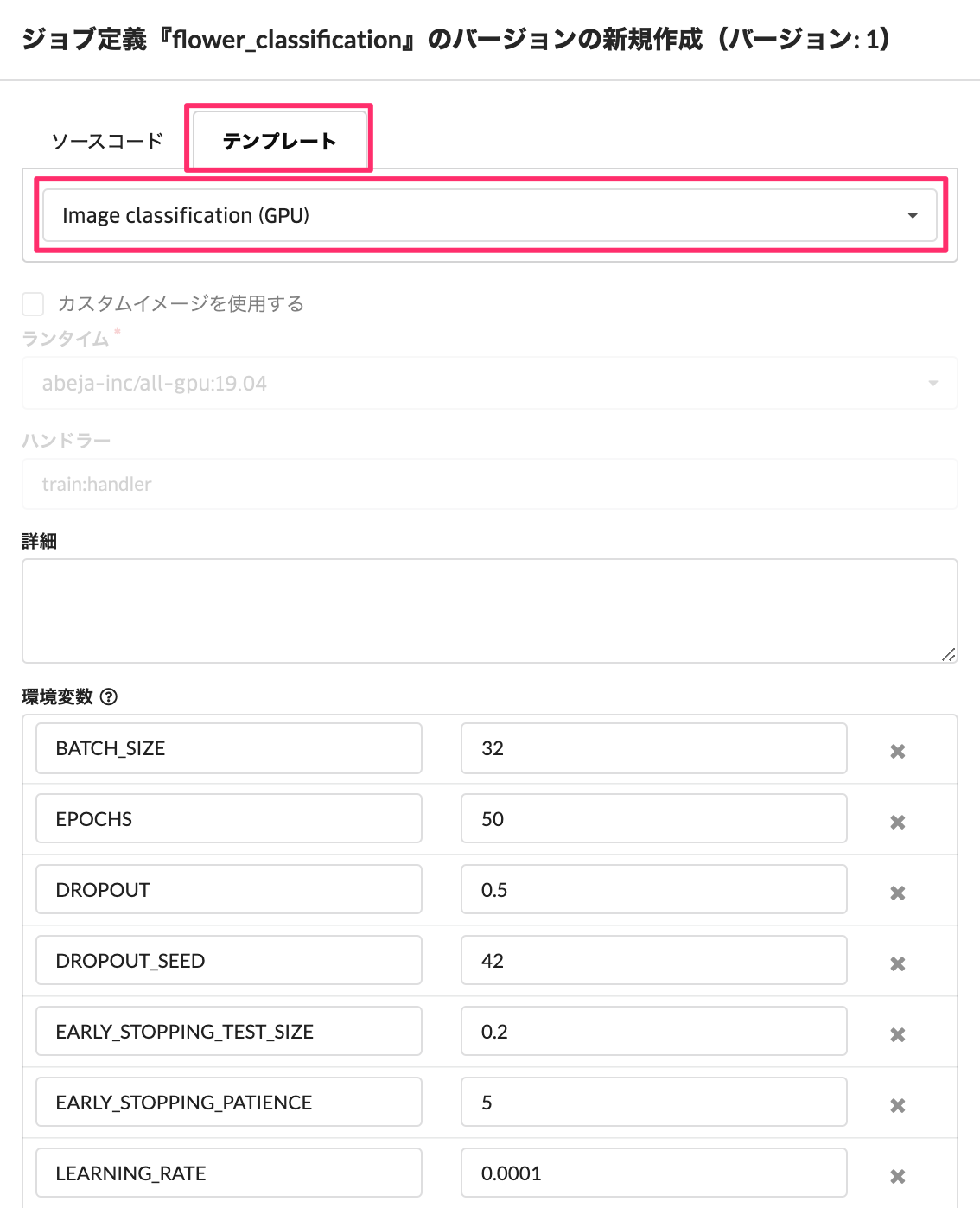
タブのテンプレートをクリックして、Image ClassificationのCPUまたはGPUを選択します。この例では GPU を選択します。この際、学習ジョブに関するデフォルトのパラメータが表示されますので、必要に応じて、調整が可能となります。 (後ほどの学習ジョブ作成時に修正も可能です。)
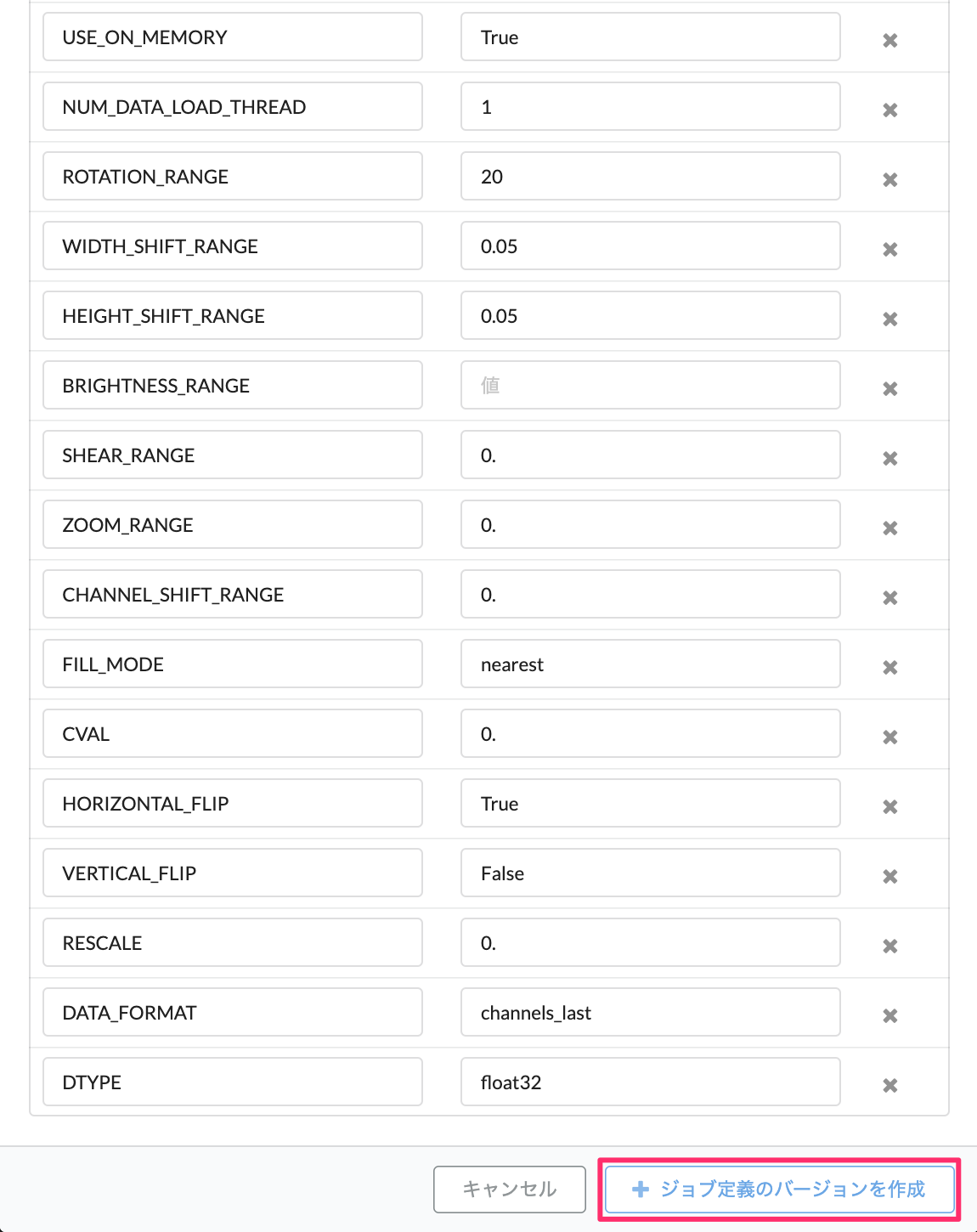
「ジョブ定義のバージョンを作成」を選択すると、ジョブのバージョン 1が作成されました。

続いて、学習ジョブを作成します。「ジョブ」をクリックして、学習ジョブを作成します。


ジョブ定義のバージョンとして、先ほど作成したバージョン1を選択します。今回はGPUを使うので、インスタンスタイプとして、gpu-1を選択します。ここで、学習に使用するデータセットを選択します。 alias ( エイリアス )は「train」と指定してください。ここでも各パラメータを調整して学習ジョブを実行することが可能です。
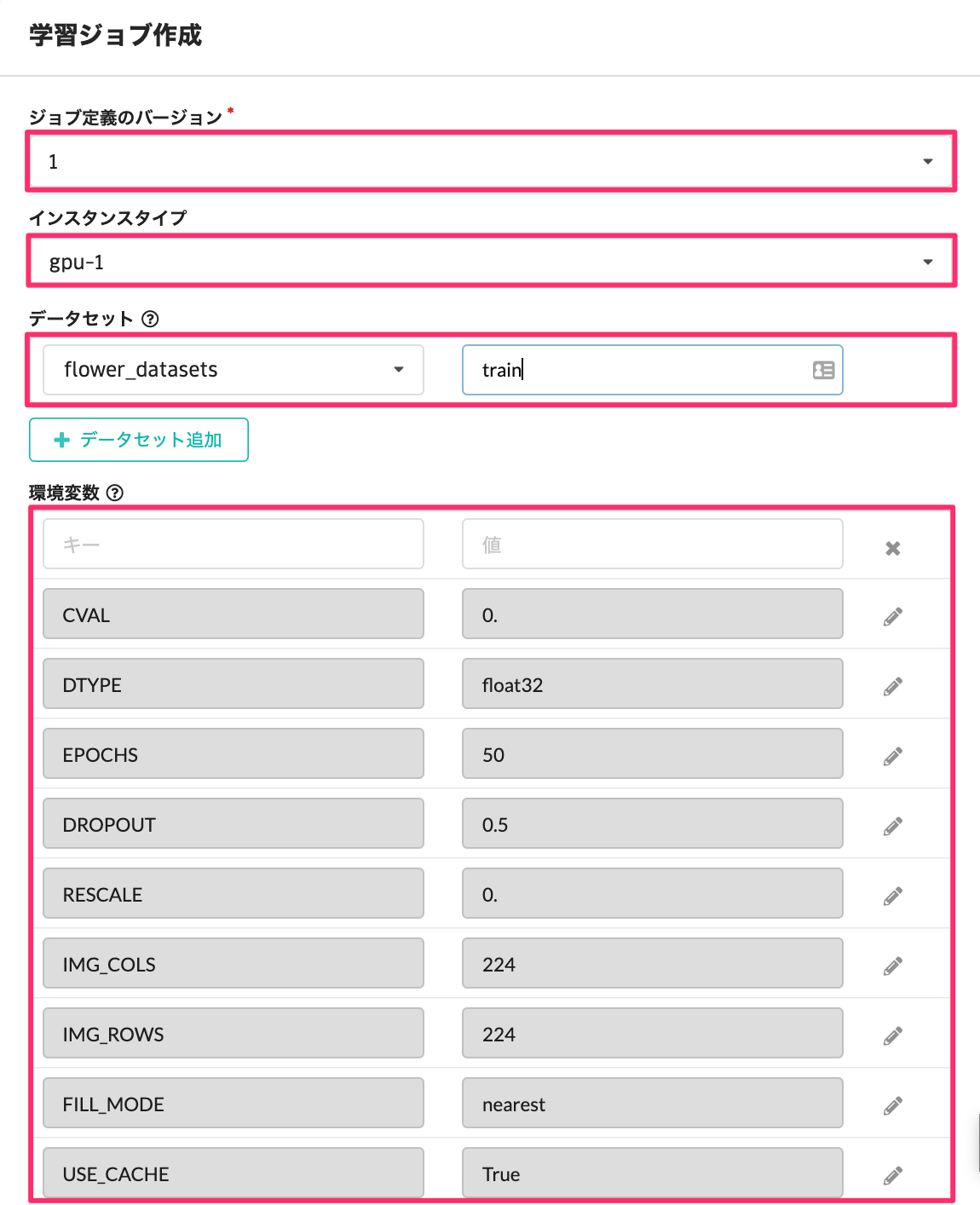
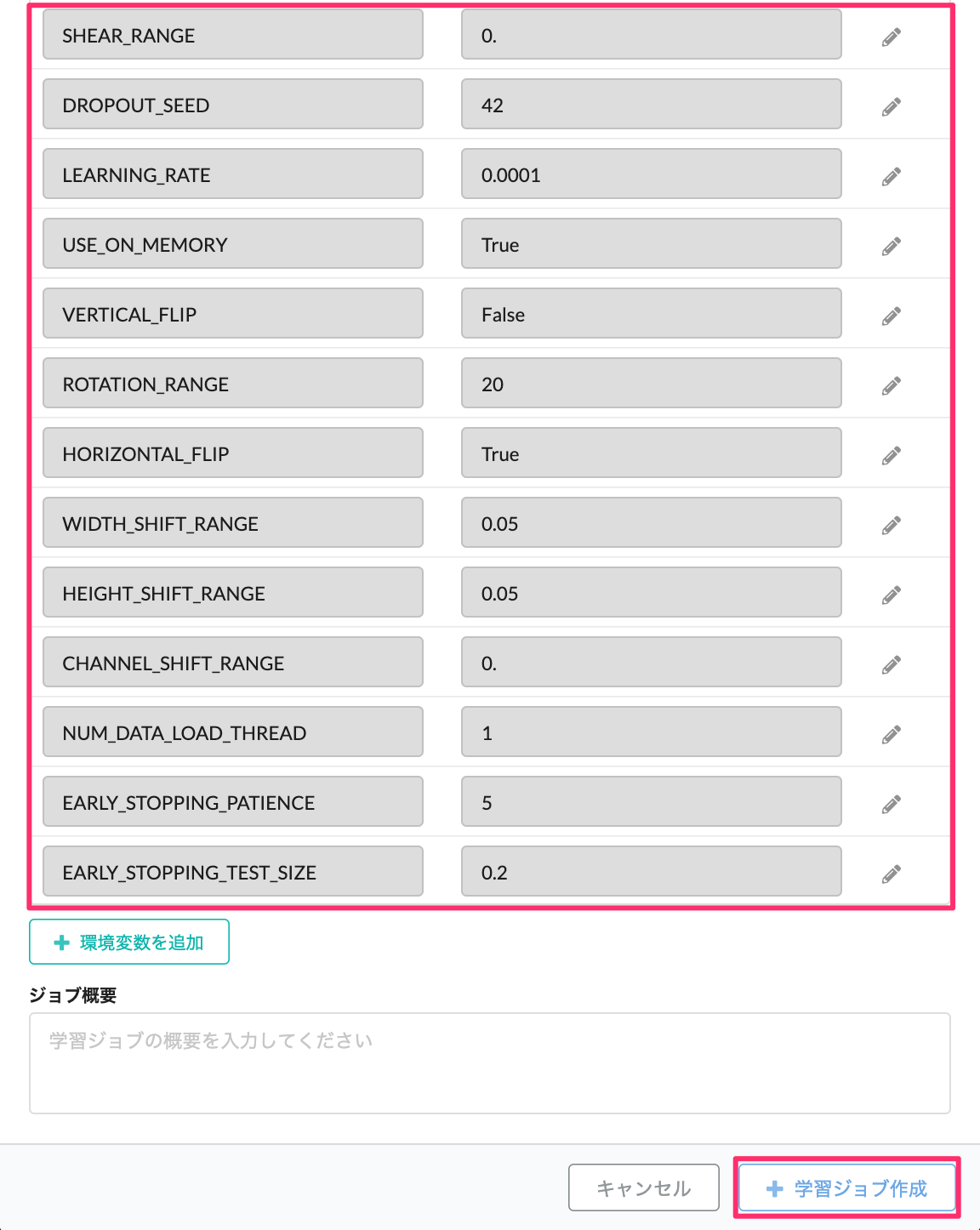
「学習ジョブ作成」を実行すると、学習ジョブが実行されます。
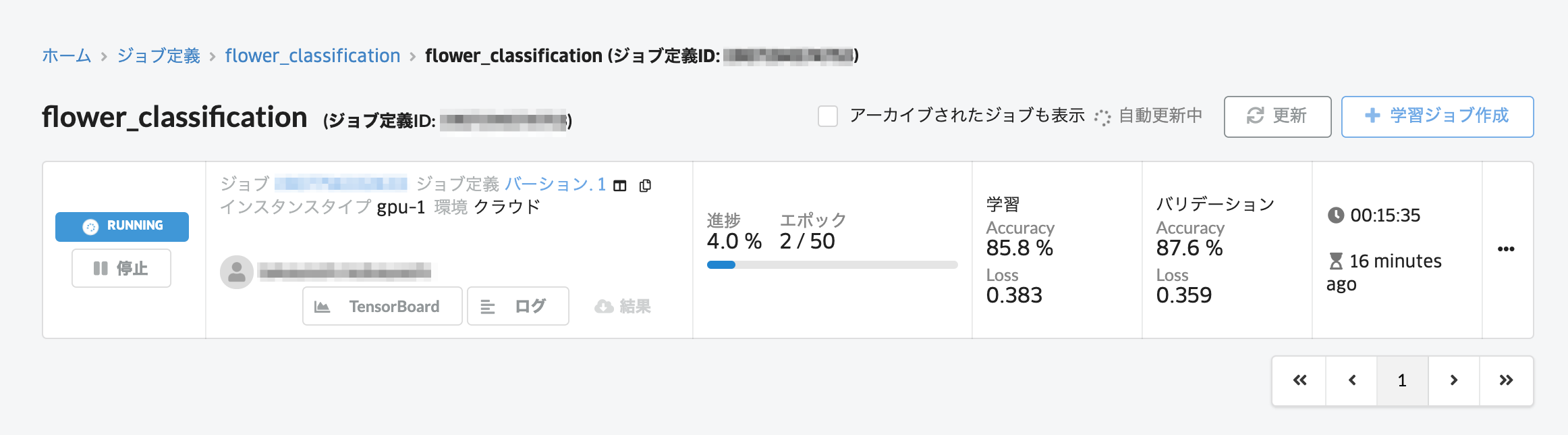
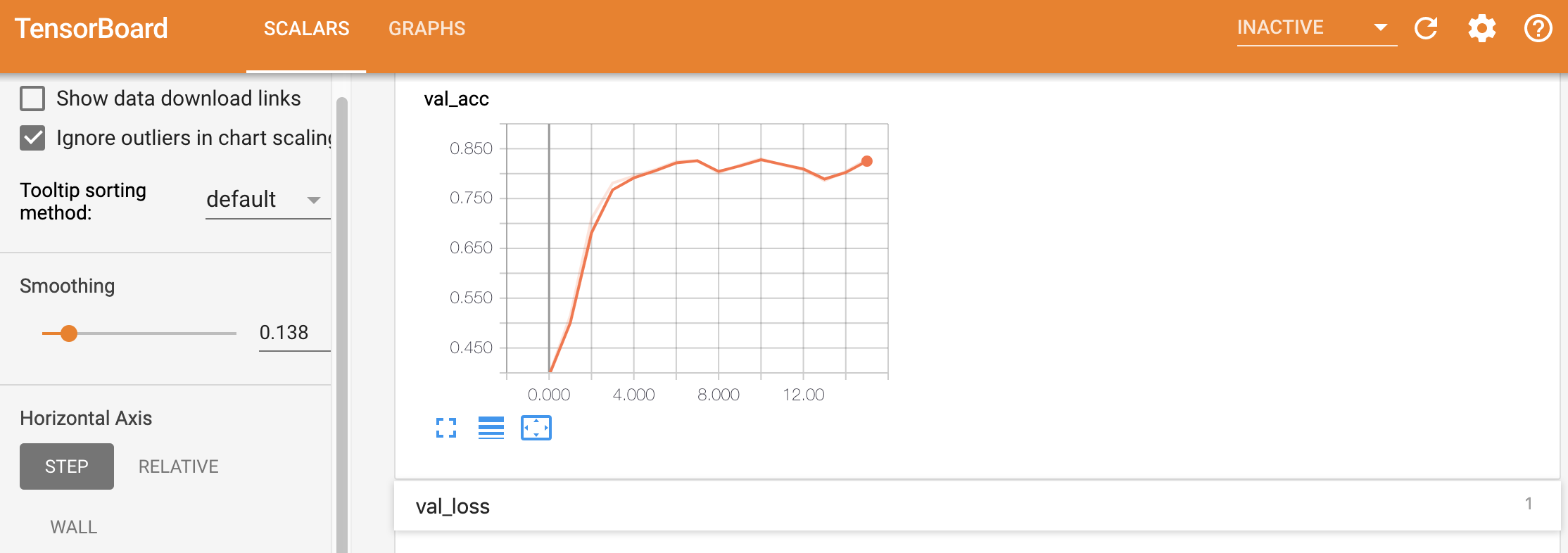
学習開始後に「TensorBoard」のボタンをクリックすると、TensorBoardの画面が開き、Training Loss, Training Accuracy, Validation Loss, Validation Accuracyのデータを可視化できます。
学習経過のログも「ログ」より閲覧いただけます。
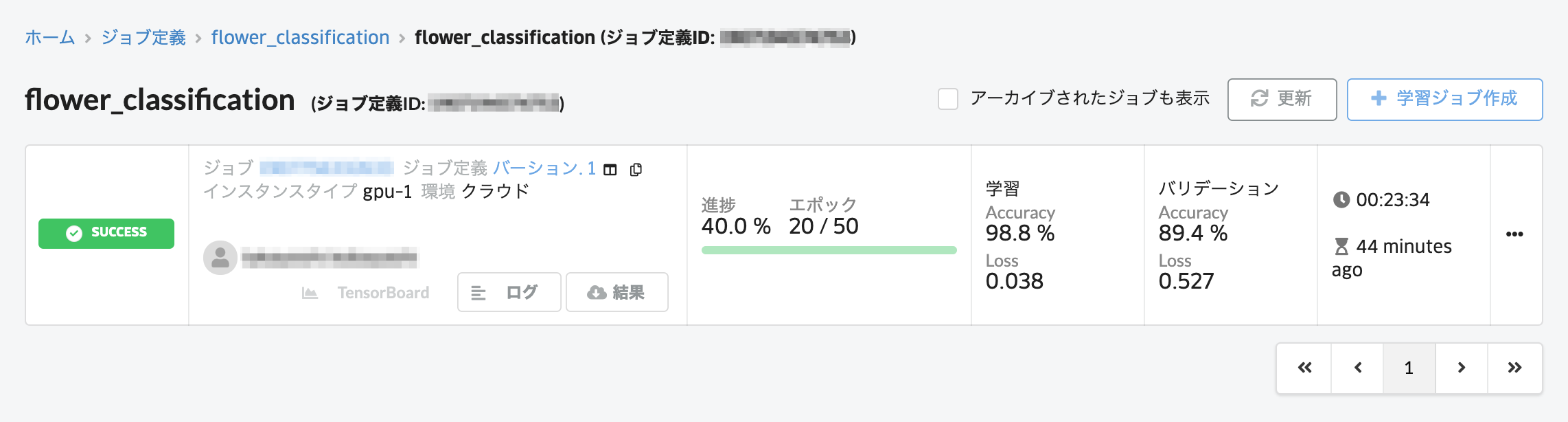
今回は20エポック目で学習がSuccessとなりました。EarlyStoppingが実装されているため、Validation Lossに変化がなくなるとその時点で学習が終了します。
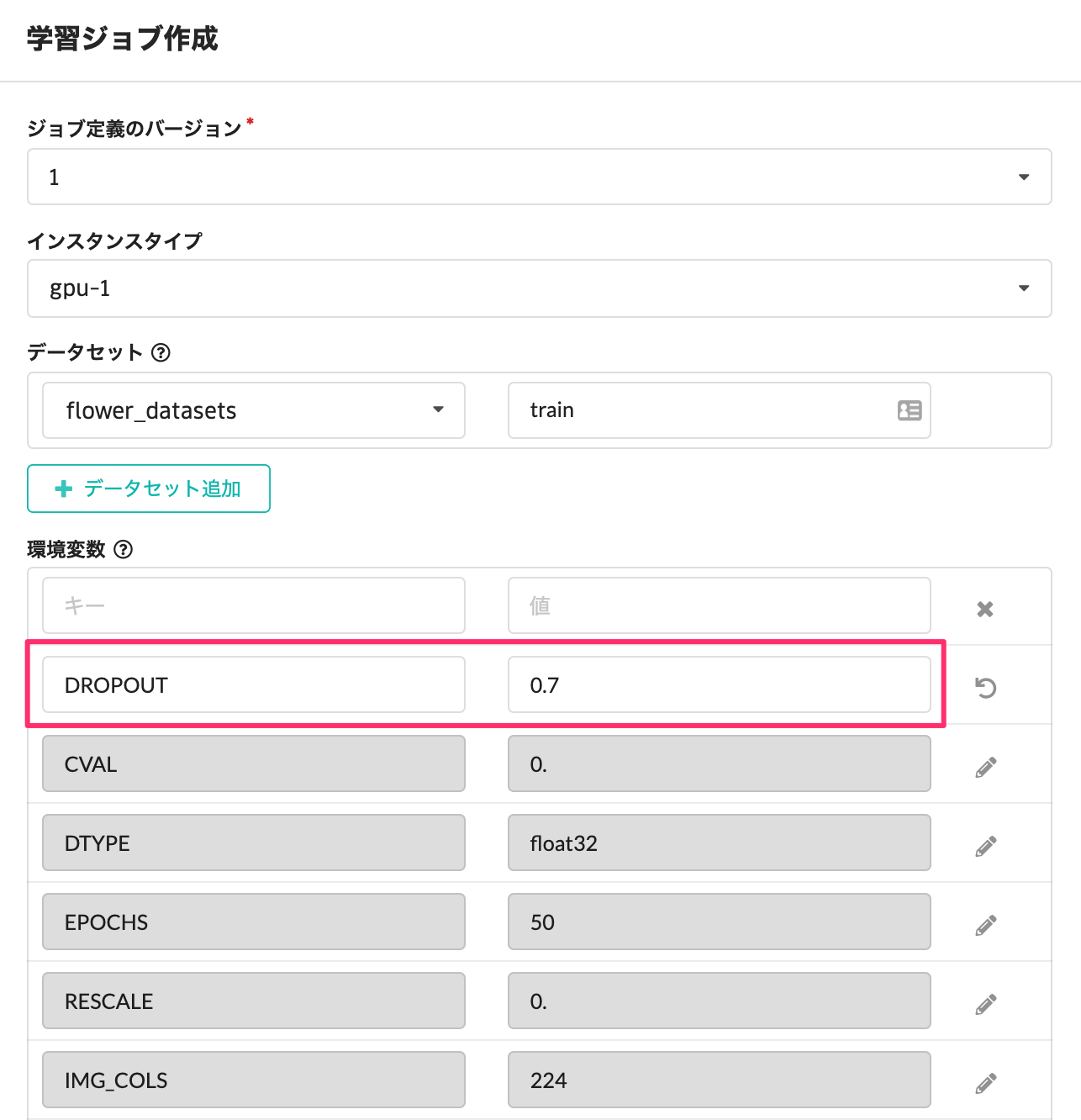
なお、このテンプレートは、各種ハイパーパラメーターをチューニングすることができます。やり方は非常に簡単で、学習ジョブを作成する画面にて、環境変数としてパラメーターを指定するだけです。指定できる環境変数の一覧は、Githubに公開しておりますこちらを参照下さい。
今回は参考にDropoutを0.7に調整し、再度学習ジョブを実行してみます。
Dropoutを0.7に変えると、Validation Accuracyが89.5%まで上がりました。
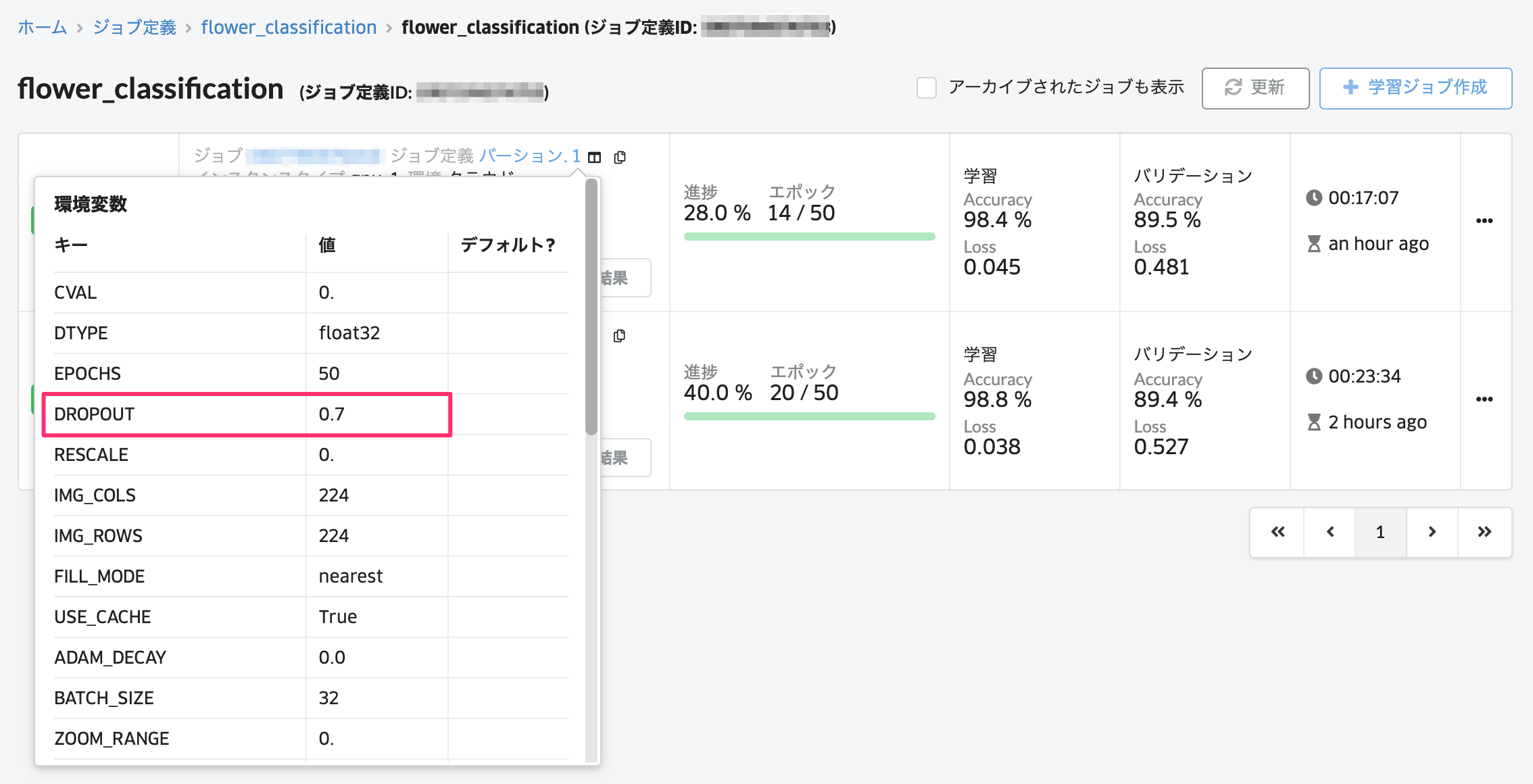
これでABEJA Template (Image Classification)を利用した学習が完了しました。
次は、”デプロイメント” を解説します。