- 概要
- スタートアップガイド
- ユーザガイド
-
リファレンス
-
ABEJA Platform CLI
- CONFIG COMMAND
- DATALAKE COMMAND
- DATASET COMMAND
- TRAINING COMMAND
-
MODEL COMMAND
- check-endpoint-image
- check-endpoint-json
- create-deployment
- create-endpoint
- create-model
- create-service
- create-trigger
- create-version
- delete-deployment
- delete-endpoint
- delete-model
- delete-service
- delete-version
- describe-deployments
- describe-endpoints
- describe-models
- describe-service-logs
- describe-services
- describe-versions
- download-versions
- run-local
- run-local-server
- start-service
- stop-service
- submit-run
- update-endpoint
- startapp command
- SECRET COMMAND
- SECRET VERSION COMMAND
-
ABEJA Platform CLI
- FAQ
- Appendix
(旧)管理画面の説明
はじめに
このページでは、アノテーションツールの管理画面・機能について説明します。
ABEJA Platform Annotation Tool 管理画面
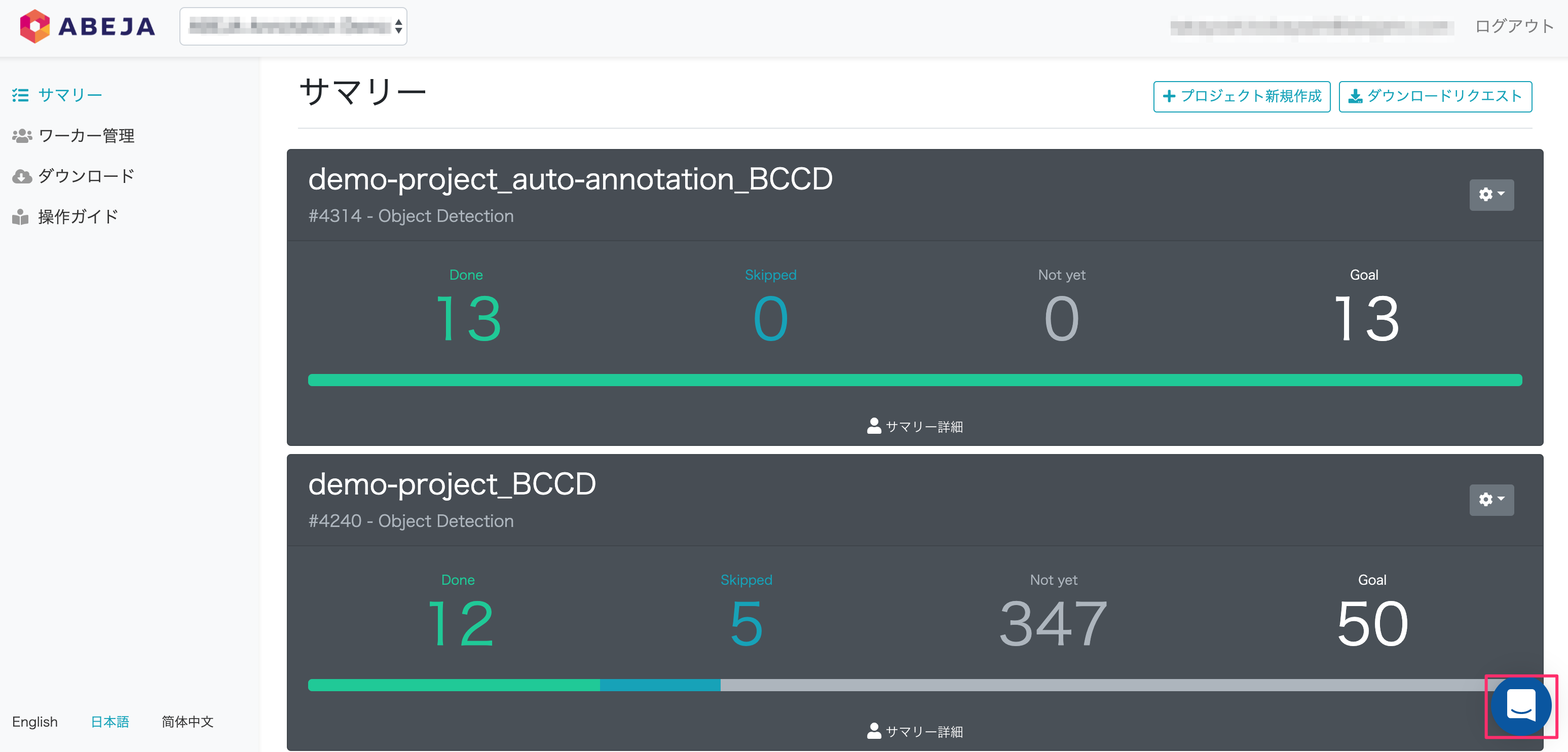
管理画面(サマリー画面)
機能概要
- 管理画面にある各機能について概要説明します。
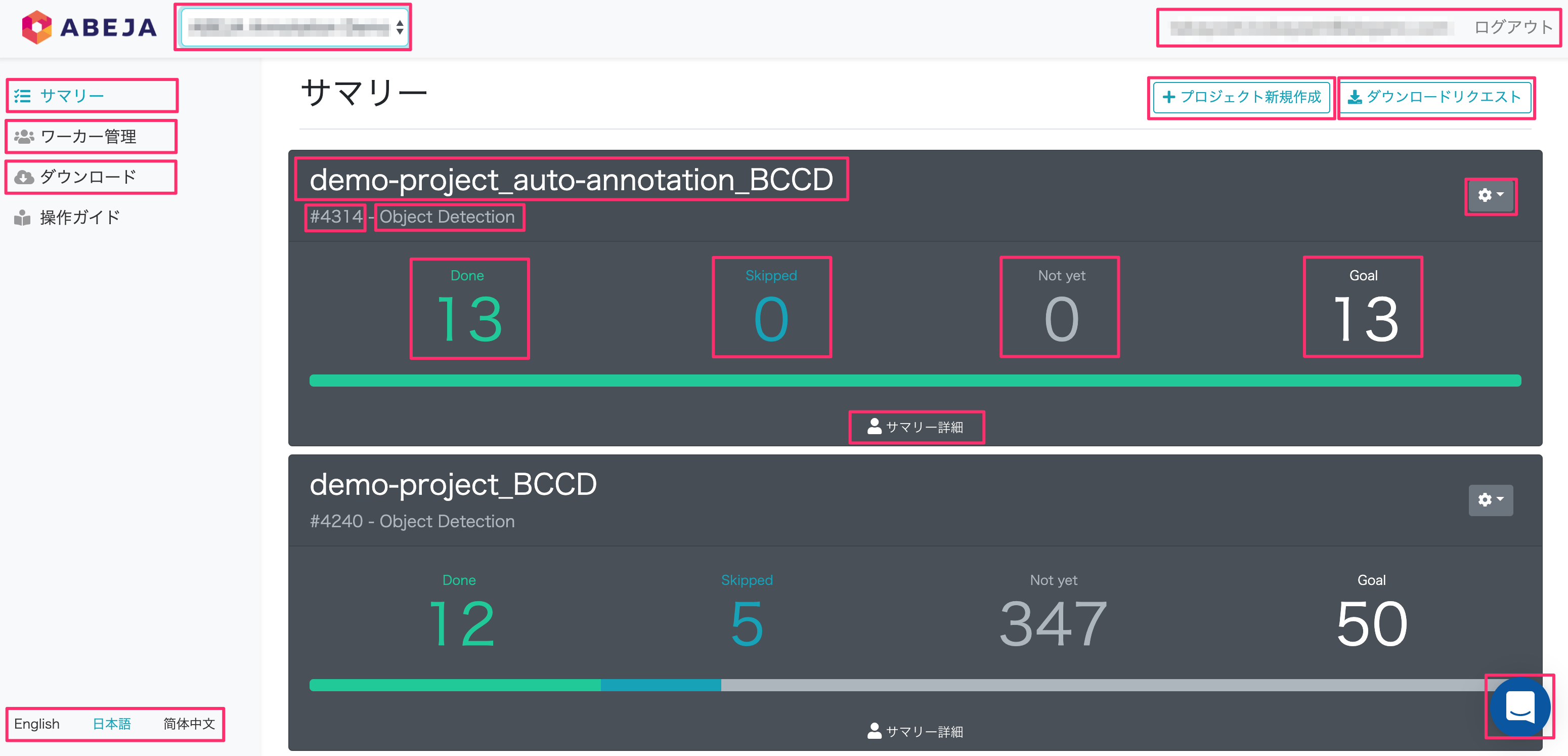
オーガ二ゼーション
- ユーザーが所属するオーガニゼーションの選択、確認ができます。
※複数のオーガニゼーションに所属している場合に限り選択可能です。
ログイン情報
- 現在のログインユーザー情報が表示されます。
サマリー
- 管理画面全体のことを指しています。(サマリー画面)
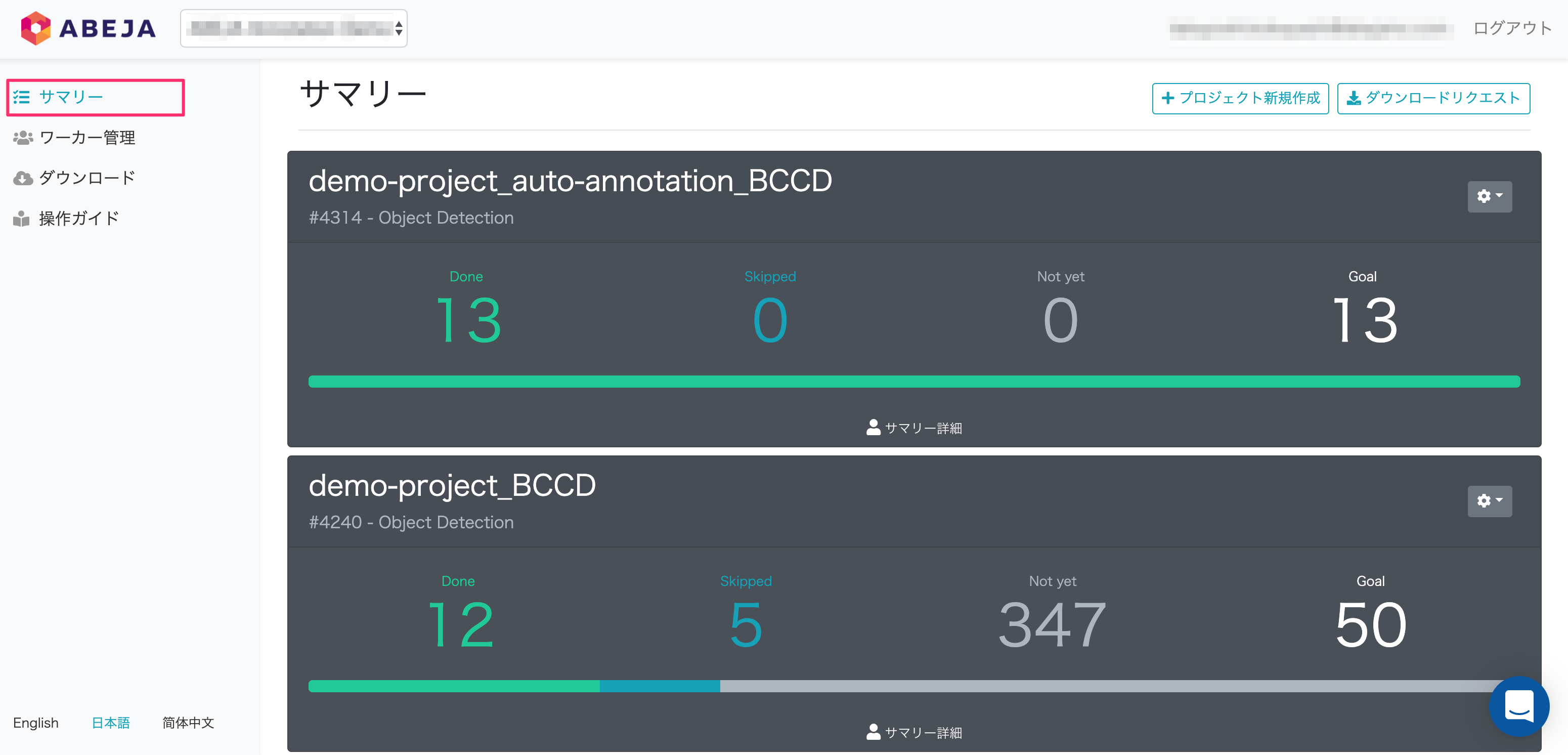
ワーカー管理
- ワーカー (アノテーター) の管理・作成・追加・編集・削除ができます。
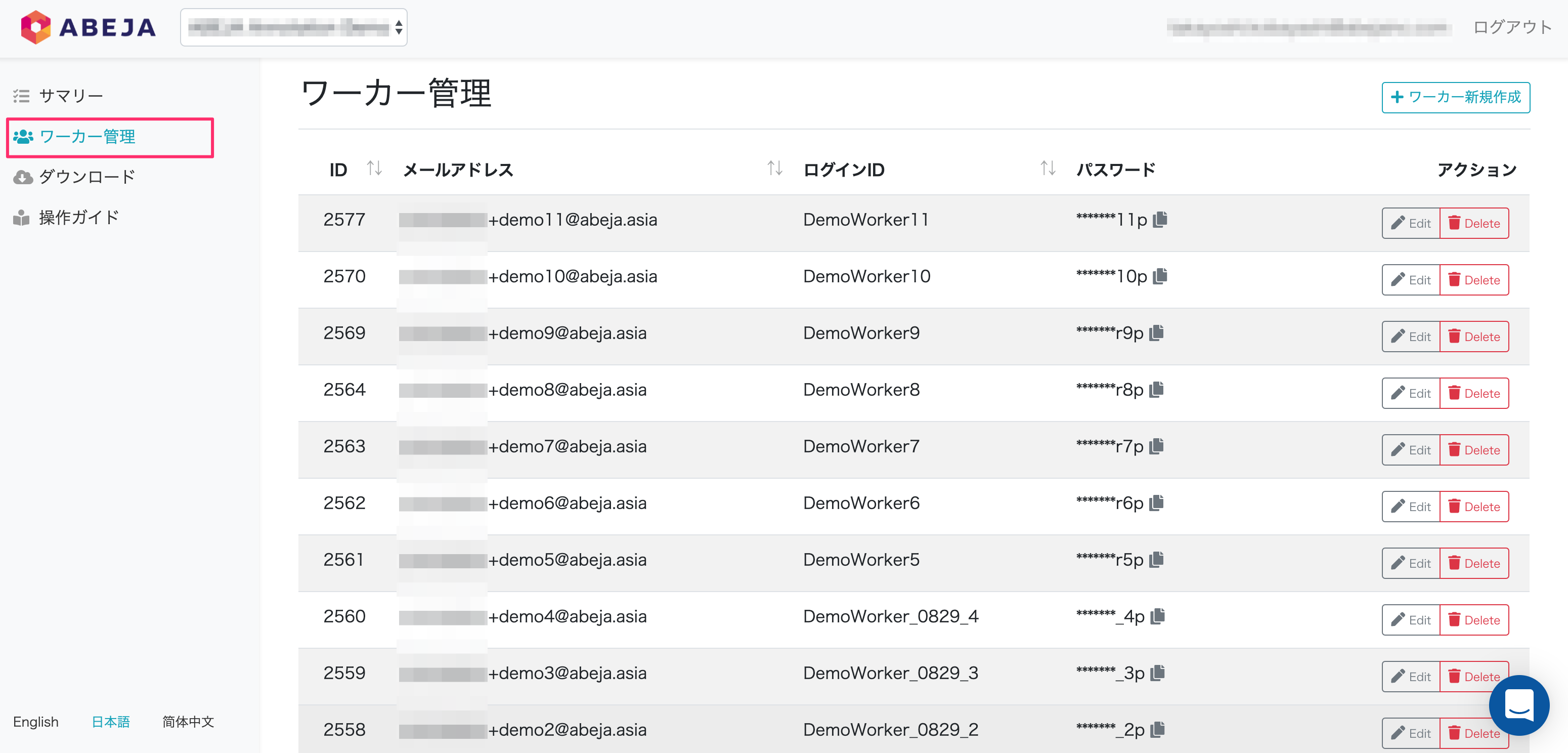
ワーカー管理画面の表示項目
| 項目 | 説明 |
|---|---|
| ID | ワーカー作成時に自動的に割り振られる識別子です。 |
| メールアドレス | ワーカー作成時に登録したメールアドレスです。※重複するメールアドレスは登録できません。 |
| ログインID | アノテーション作業用のログインIDです。※重複するログインID名は登録できません。 |
| パスワード | アノテーション作業用のログインパスワードです。コピーアイコンをクリックするとワーカーのパスワードがクリップボードに保存されます。 |
| アクション | 「Edit」ボタンクリックでワーカー情報の確認、編集ができます。「Delete」ボタンクリックでワーカーの削除ができます。 |
| ワーカー新規作成 | ワーカーを新規に作成することができます。 |
※ワーカー作成手順はこちらを参照ください。
ダウンロード
- ダウンロードリクエストの進捗状況が確認できます。状態が完了済み(ダウンロード)の場合はローカルへ保存することができます。
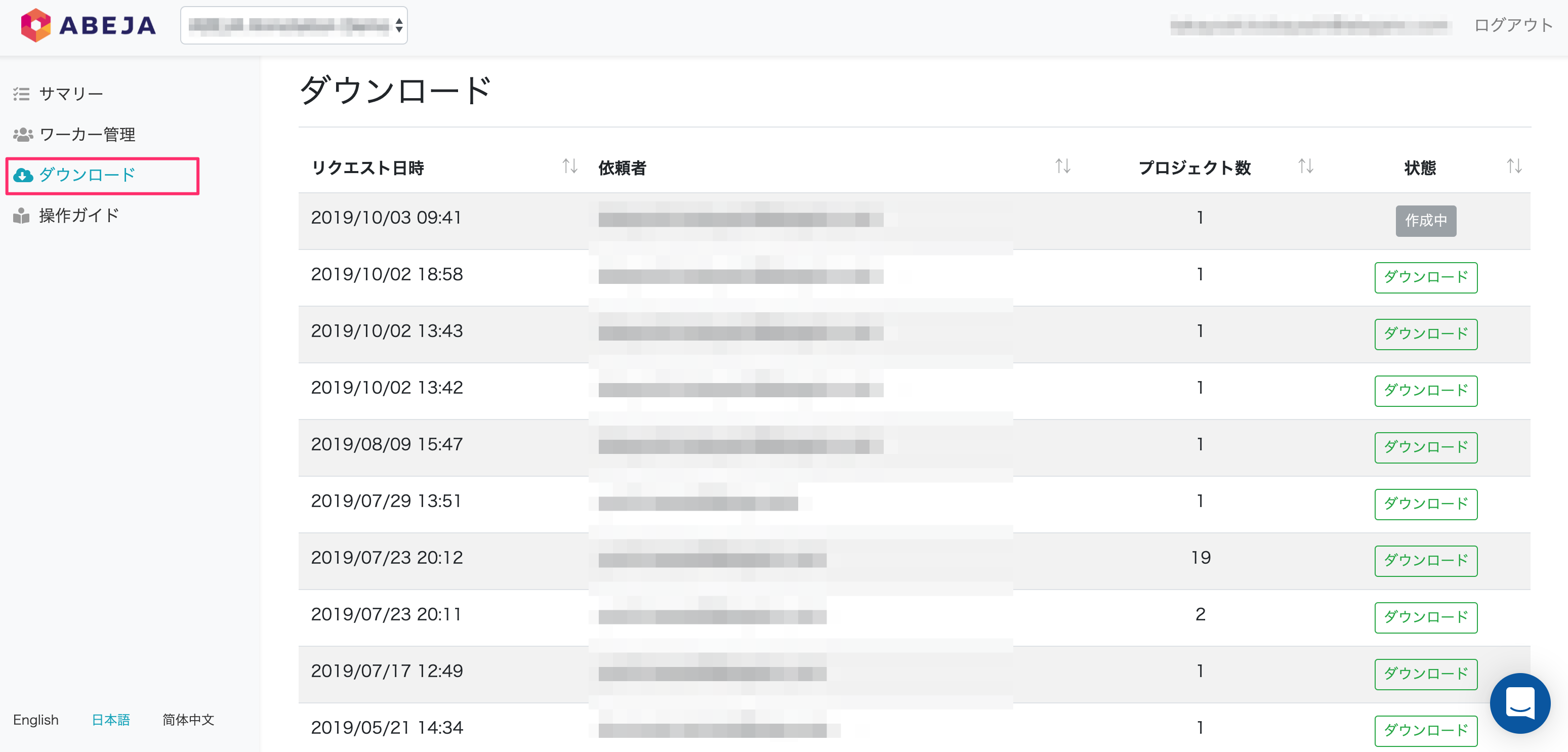
ダウンロードについての詳細は 結果をダウンロードする を参照ください。
プロジェクト新規作成
- 実際にアノテーション作業を行うためのプロジェクトが作成できます。
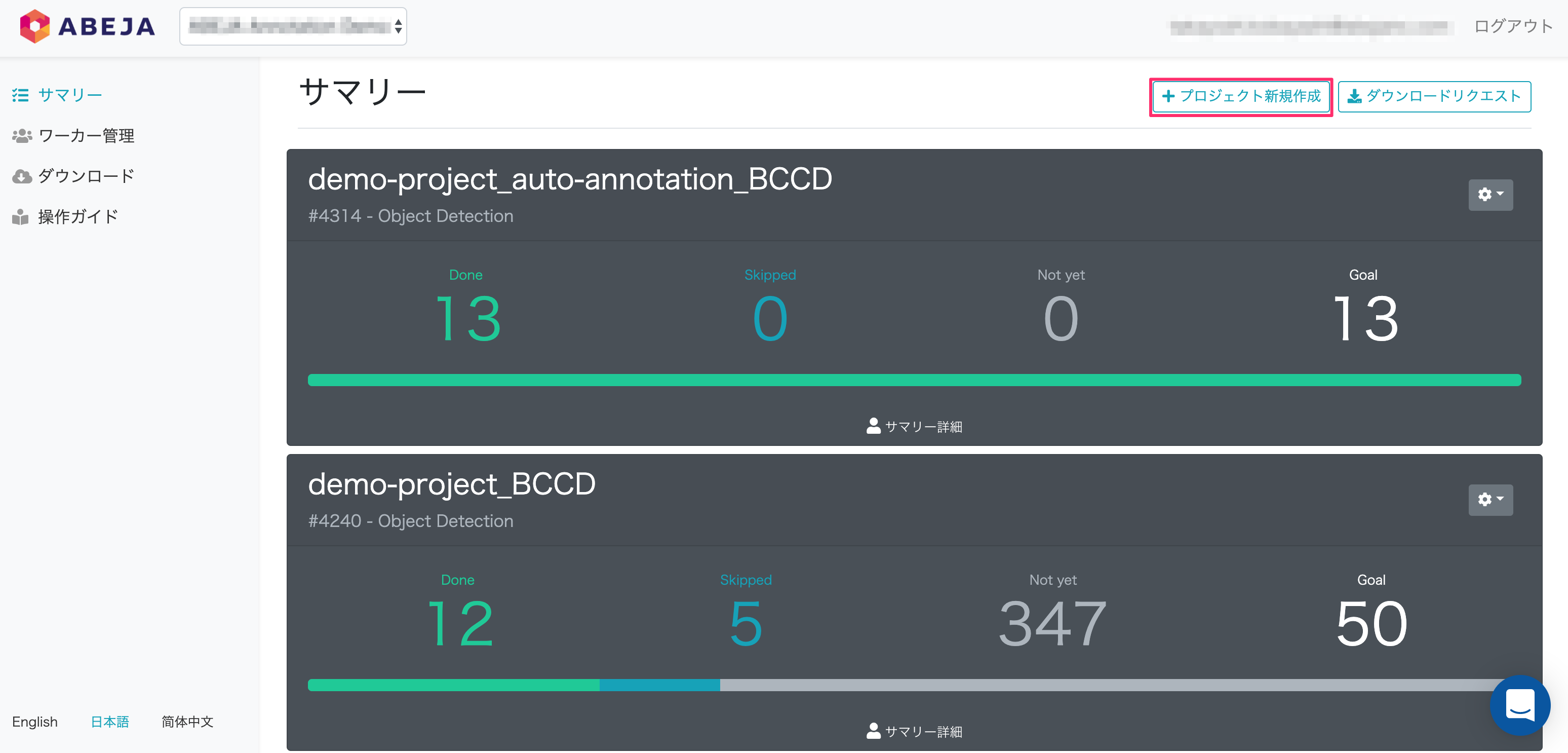
※ プロジェクト作成手順はこちらを参照ください。
ダウンロードリクエスト
- アノテーション結果をJSON形式でダウンロードします。
ダウンロードについての詳細は 結果をダウンロードする をご参照下さい。
プロジェクト名
- 学習のために任意に設定したプロジェクトの名前です。
プロジェクトID
- プロジェクト作成時に自動付与される識別子です。
テンプレートタイプ
- プロジェクト作成時に設定した学習データ抽出のためのテンプレートの種類です。
ABEJAが提供しているテンプレートの種類一覧、詳細はこちらを参照ください。
ギアアイコン
- 対象プロジェクトの拡張機能アイコンです。
プロジェクト内の右上に位置する 歯車のアイコン をクリックすると、プロジェクトの拡張機能が表示されます。
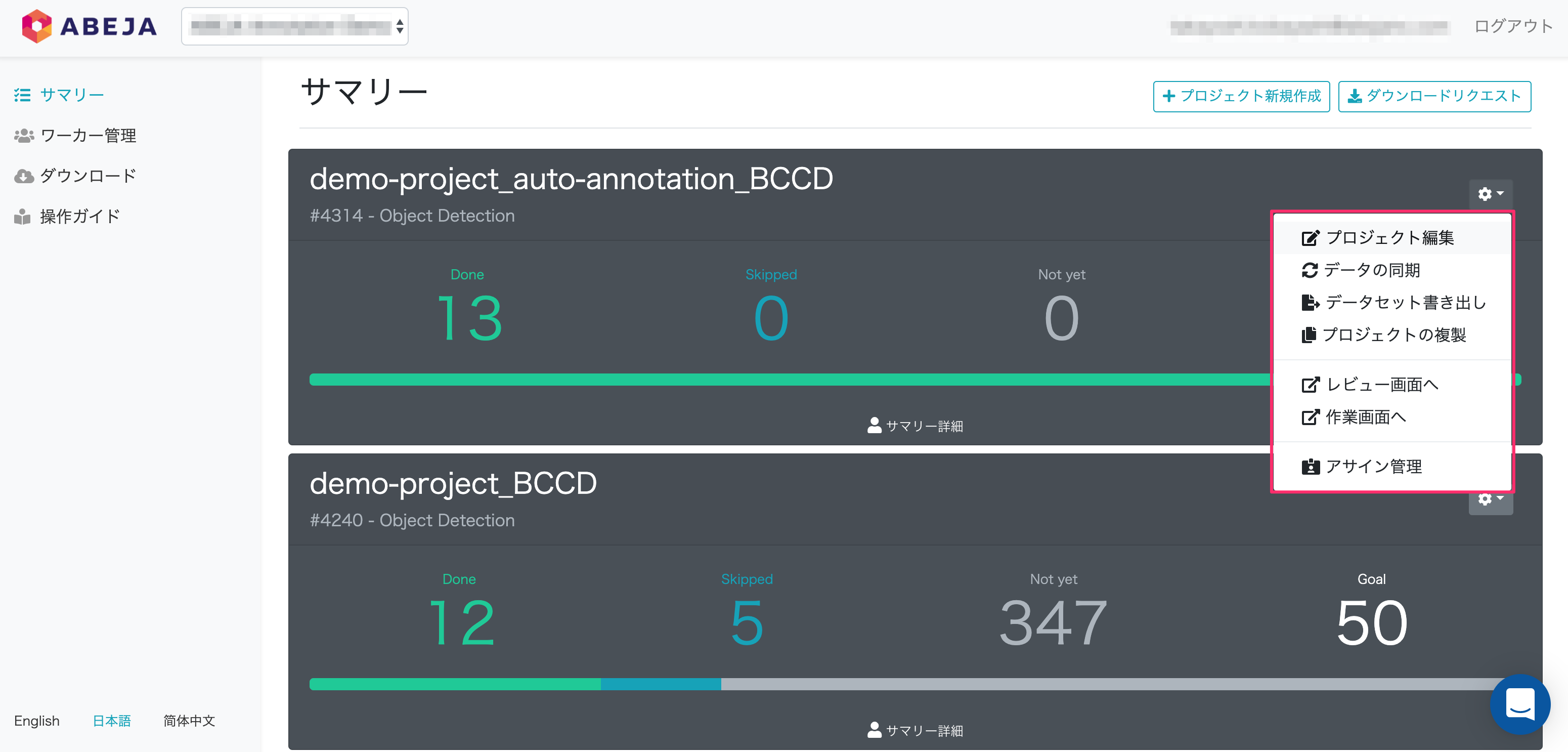
ギアアイコンで表示される項目
| 項目 | 説明 |
|---|---|
| プロジェクト編集 | プロジェクト内容の確認、編集ができます。 |
| データの同期 | プロジェクトで利用するDataLake Channelとのデータの同期を行います。 |
| データセット書き出し | プロジェクトのデータセットを書き出すことができます。 |
| プロジェクトの複製 | 既存のプロジェクトを複製することができます。 ※指定したDataLake Channelは引き継がれません。 |
| レビュー画面へ | Annotation Toolのレビュー画面へ移動します。 |
| 作業画面へ | Annotation Toolの作業画面へ移動します。 |
| アサイン管理 | アサイン管理画面へ遷移します。 |
Done
- 対象プロジェクトにおけるOK(完了)タスク数です。アノテーション済みのタスクの数が確認できます。
Skipped
- 対象プロジェクトにおけるタスクをスキップした数です。
Not yet
- 対象プロジェクトにおけるアノテーション未完了の残タスク数です。
※画像の場合、プロジェクトの残タスク数はない状態となります。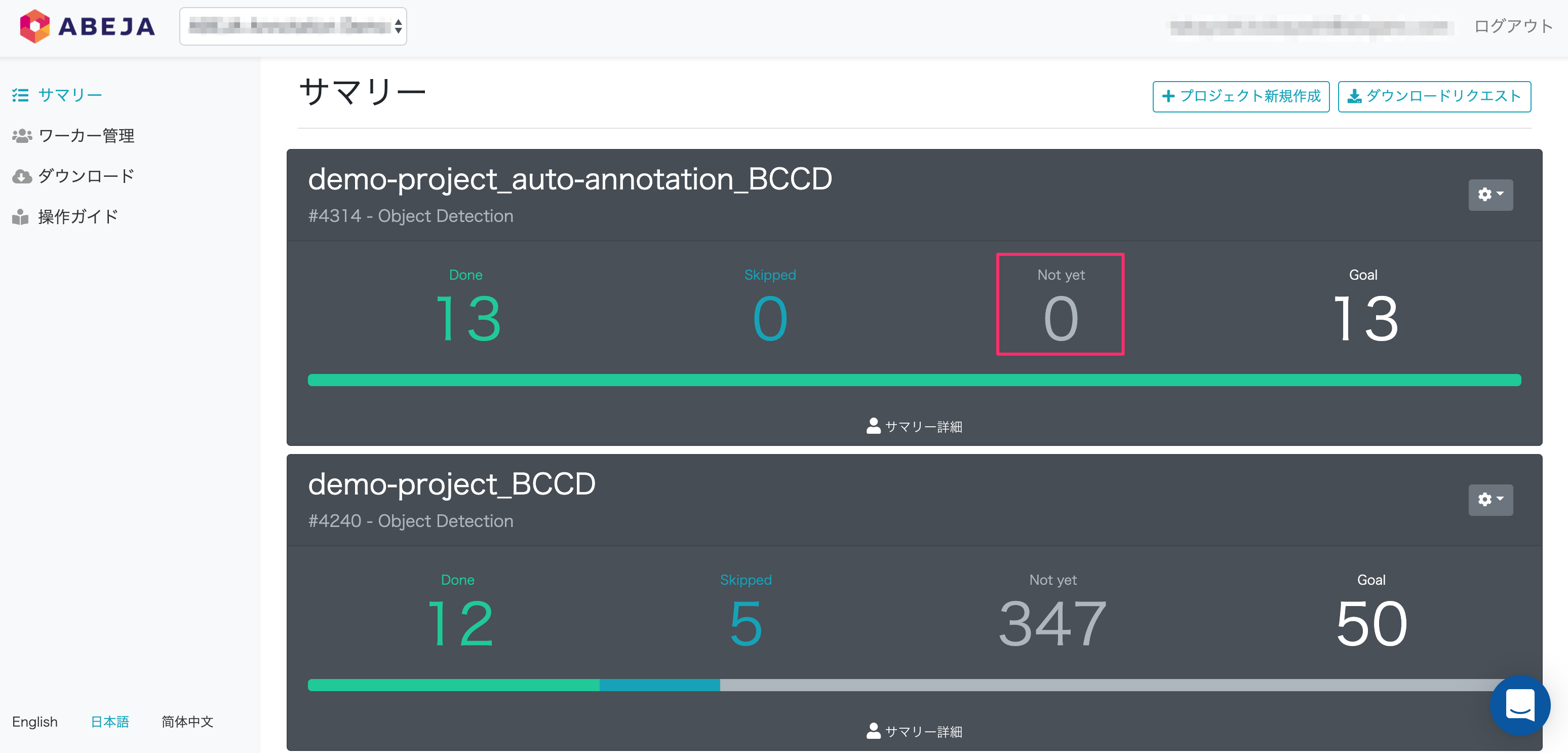
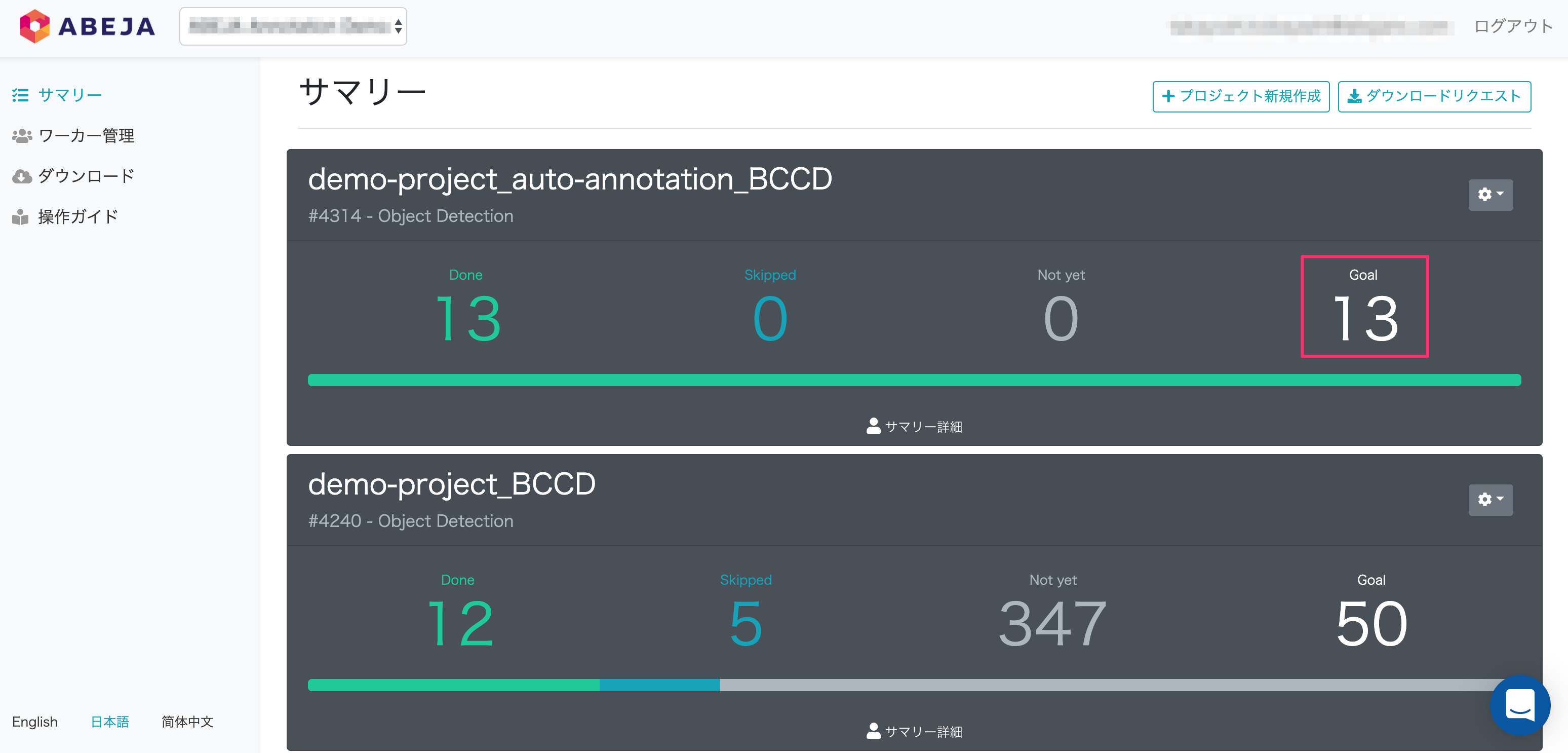
Goal
- 対象プロジェクトにおけるアノテーションの最終目標タスク数です。
サマリー詳細
対象プロジェクトのタスク進捗詳細が表示されます。
サマリー詳細では、ワーカー単位の作業状況を閲覧することができます。
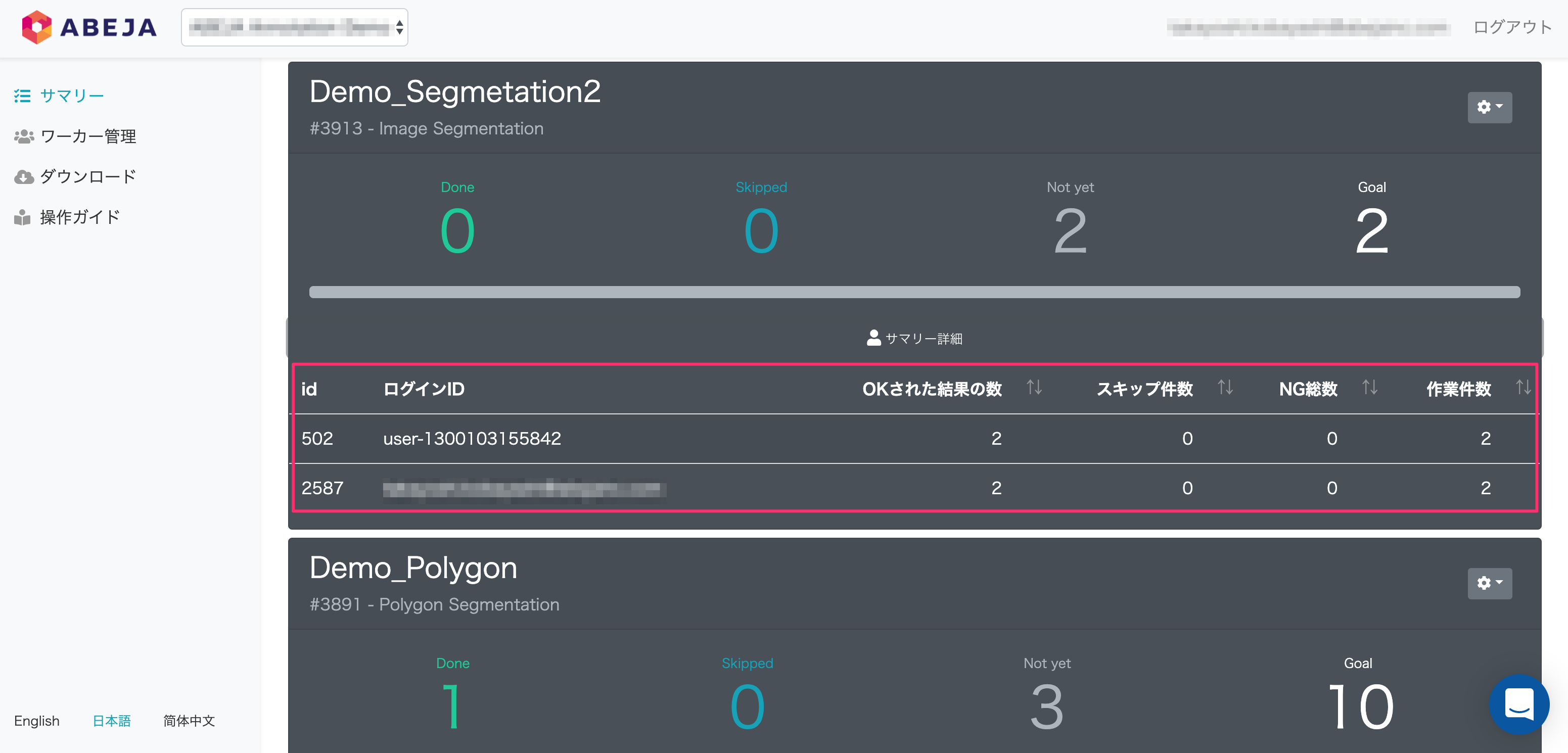
サマリー詳細で表示される項目
| 項目 | 説明 |
|---|---|
| ID | ログインユーザーの識別子 |
| ログインID | プロジェクトにログインしたワーカー表示名(アノテーター) |
| OKされた結果の数 | アノテーション作業が完了したタスクの数 |
| スキップ件数 | アノテーション対象外等でスキップしたタスクの数 |
| NG総数 | アノテーション結果に不備がある等で差し戻されたタスクの数 |
| 作業件数 | OK+スキップの合計数 |
言語切り替え
- 表示言語の切り替えが可能です。英語、日本語、简体中文を選択できます。
チャットアイコン
- アノテーションツールに関するお問い合わせをチャット方式で行えます。