- 概要
- スタートアップガイド
- ユーザガイド
-
リファレンス
-
ABEJA Platform CLI
- CONFIG COMMAND
- DATALAKE COMMAND
- DATASET COMMAND
- TRAINING COMMAND
-
MODEL COMMAND
- check-endpoint-image
- check-endpoint-json
- create-deployment
- create-endpoint
- create-model
- create-service
- create-trigger
- create-version
- delete-deployment
- delete-endpoint
- delete-model
- delete-service
- delete-version
- describe-deployments
- describe-endpoints
- describe-models
- describe-service-logs
- describe-services
- describe-versions
- download-versions
- run-local
- run-local-server
- start-service
- stop-service
- submit-run
- update-endpoint
- startapp command
- SECRET COMMAND
- SECRET VERSION COMMAND
-
ABEJA Platform CLI
- FAQ
- Appendix
(旧)事前推論機能
事前推論の登録にはプロジェクトの作成が完了している必要があります。
プロジェクト作成後、以下の情報を確認して下さい。
- ANNOTATION_MANAGER_USER_ID : アノテーションのManagerユーザーアカウントのID
- ANNOTATION_MANAGER_ACCESS_TOKEN : アノテーションのManagerユーザーのアクセストークン
- ANNOTATION_ORGANIZATION_ID : アノテーションツール上の組織ID
- ANNOTATION_PROJECT_ID : アノテーションプロジェクトのID
- ABEJA_PLATFORM_USER_ID : ABEJA Platformのuser- から始まるユーザーID
- ABEJA_PLATFORM_PERSONAL_ACCESS_TOKEN : ABEJA Platformユーザーのアクセストークン
事前推論結果の登録方法
1. 事前推論登録用の以下のエンドポイントに対し、POSTリクエストを実行します。 スキーマはテンプレート毎に異なります。事前登録に必要なスキーマの情報はアノテーション結果 (サンプル)を参照ください。
https://annotation-tool.abeja.io//api/v1/organizations/<organization-id>/projects/<project-id>/tasks/<task-id>/preinferences
2. 以下のコマンドを実行します。 各種ファイルは下部のサンプルコードをご参照ください。
$ pip install -r requirements.txt
$ wget https://github.com/yuyu2172/share-weights/releases/download/0.0.3/ssd300_voc0712_2017_06_06.npz
$ export ANNOTATION_ORGANIZATION_ID=<your-organization-id>
$ export ANNOTATION_ACCESS_USER_ID=<your-user-id>
$ export ANNOTATION_ACCESS_TOKEN=<your-access-token>
$ export ANNOTATION_PROJECT_ID=<your-project-id>
$ export ABEJA_PLATFORM_USER_ID=<your-ABEJA-Platform-user-id>
$ export ABEJA_PLATFORM_PERSONAL_ACCESS_TOKEN=<your-ABEJA-Platform-access-token>
$ python register_preinference.py
3. 登録に成功すると以下のように作業画面に推論結果が表示されます。
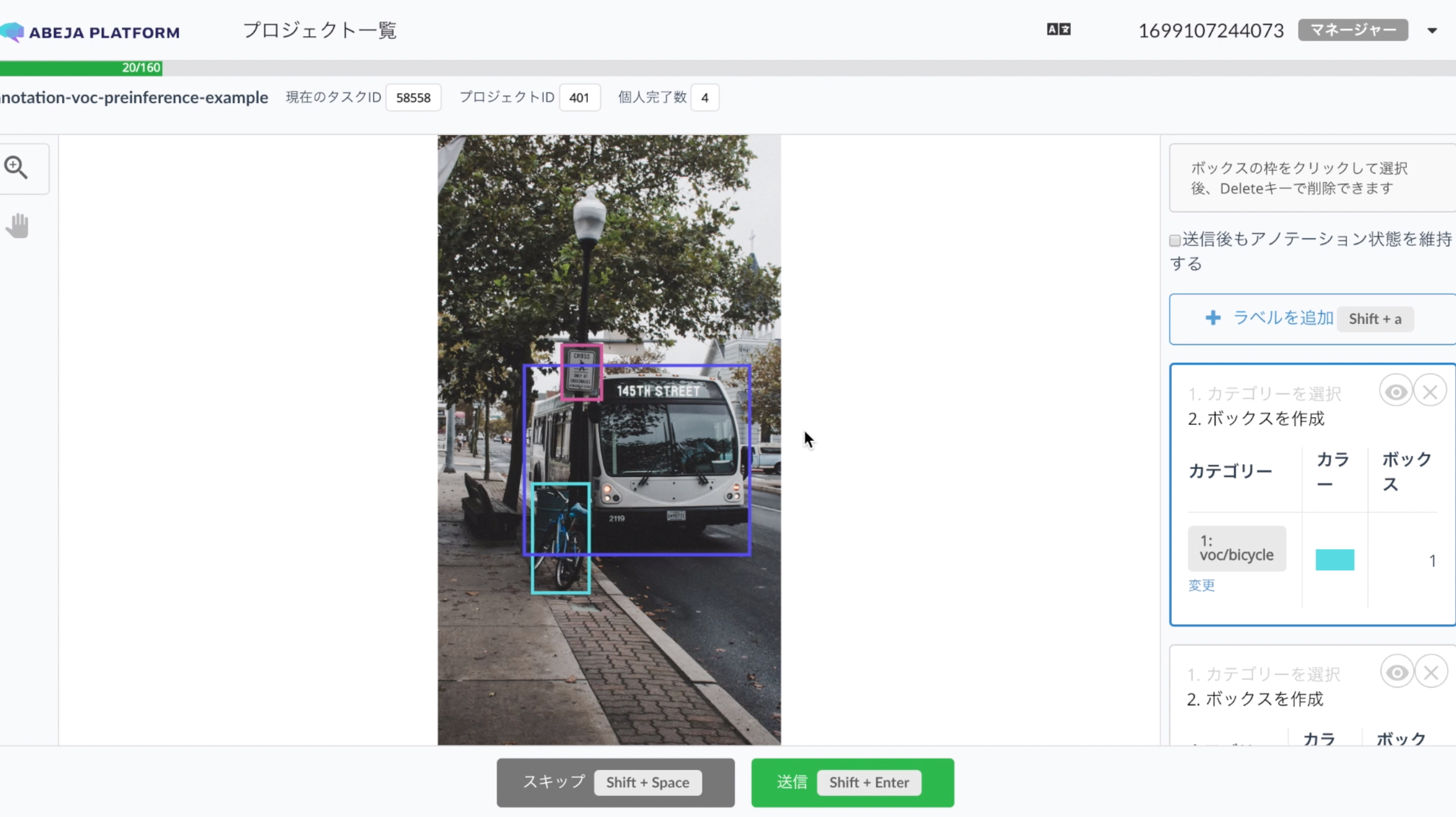
サンプルコード
スクリプトから各タスクに対する事前推論結果を登録します。
以下は chainercv を使用したサンプルコードです。
- プロジェクトのラベル登録
{
"attributes": [
{
"id": 0,
"name": "voc",
"categories": [
{
"id": 0,
"name": "aeroplane"
},
{
"id": 1,
"name": "bicycle"
},
{
"id": 2,
"name": "bird"
},
{
"id": 3,
"name": "boat"
},
{
"id": 4,
"name": "bottle"
},
{
"id": 5,
"name": "bus"
},
{
"id": 6,
"name": "car"
},
{
"id": 7,
"name": "cat"
},
{
"id": 8,
"name": "chair"
},
{
"id": 9,
"name": "cow"
},
{
"id": 10,
"name": "diningtable"
},
{
"id": 11,
"name": "dog"
},
{
"id": 12,
"name": "horse"
},
{
"id": 13,
"name": "motorbike"
},
{
"id": 14,
"name": "person"
},
{
"id": 15,
"name": "pottedplant"
},
{
"id": 16,
"name": "sheep"
},
{
"id": 17,
"name": "sofa"
},
{
"id": 18,
"name": "train"
},
{
"id": 19,
"name": "tvmonitor"
}
]
}
],
"isMultipleSelection": false
}
- requirements.txt
chainercv==0.11.0
abeja-sdk==0.1.3
- register_inference.py
import os
import io
from urllib.parse import urljoin
from abeja.datalake import Client as DatalakeClient
import requests
from PIL import Image
import numpy as np
from chainercv.datasets import voc_bbox_label_names
from chainercv.links import SSD300
from chainercv.visualizations import vis_bbox
ANNOTATION_API = os.environ.get('ANNOTATION_API', 'https://annotation-tool.abeja.io')
ANNOTATION_ACCESS_USER_ID = os.environ.get('ANNOTATION_ACCESS_USER_ID')
ANNOTATION_ACCESS_TOKEN = os.environ.get('ANNOTATION_ACCESS_TOKEN')
ANNOTATION_ORGANIZATION_ID = os.environ.get('ANNOTATION_ORGANIZATION_ID')
ANNOTATION_PROJECT_ID = os.environ.get('ANNOTATION_PROJECT_ID')
headers = {
'api-access-user-id': ANNOTATION_ACCESS_USER_ID,
'api-access-token': ANNOTATION_ACCESS_TOKEN
}
FIXED_CATEGORY_ID = 0
def main():
# ABEJA Platformの組織IDを取得します
organization_url = urljoin(ANNOTATION_API, "/api/v1/organizations/{}".format(ANNOTATION_ORGANIZATION_ID))
res = requests.get(organization_url, headers=headers)
res.raise_for_status()
platform_organization_id = res.json()['id']
# ABEJA Platform上でアノテーション対象ファイルが格納されているChannelのIDを取得します
organization_url = urljoin(ANNOTATION_API, "/api/v1/organizations/{}/projects/{}".format(ANNOTATION_ORGANIZATION_ID, ANNOTATION_PROJECT_ID))
res = requests.get(organization_url, headers=headers)
res.raise_for_status()
platform_datalake_channel_id = res.json()['data_lake_channels'][0]['channel_id']
# ABEJA PlatformのSDKを使用します
client = DatalakeClient(organization_id=platform_organization_id)
datalake_channel = client.get_channel(platform_datalake_channel_id)
# wget https://github.com/yuyu2172/share-weights/releases/download/0.0.3/ssd300_voc0712_2017_06_06.npz
pretrained_model = 'ssd300_voc0712_2017_06_06.npz'
model = SSD300( n_fg_class=len(voc_bbox_label_names), pretrained_model=pretrained_model)
task_url = urljoin(ANNOTATION_API, "/api/v1/organizations/{}/projects/{}/tasks/".format(ANNOTATION_ORGANIZATION_ID, ANNOTATION_PROJECT_ID))
page = 1
while True:
res = requests.get(task_url, headers=headers, params={'page': page})
res.raise_for_status()
res_body = res.json()
if len(res_body) == 0:
break
for task in res_body:
metadata = task['metadata'][0]
# タスクのアノテーション対象画像ファイルをダウンロードします
file = datalake_channel.get_file(metadata['file_id'])
img_io = io.BytesIO(file.get_content())
img = np.array(Image.open(img_io))
img = img.transpose(2, 0, 1)
try:
# 推論を行います
bboxes, labels, scores = model.predict([img])
except:
continue
information = []
for bbox, label in zip(bboxes, labels):
for b, l in zip(bbox, label):
y_min, x_min, y_max, x_max = tuple(b.tolist())
rect = [
x_min,
y_min,
x_max,
y_max
]
information.append({
'rect': rect,
'classes': [
{
'id': int(l),
'name': voc_bbox_label_names[l],
'category_id': FIXED_CATEGORY_ID
}
]
})
if len(information) == 0:
continue
preinference_url = urljoin(task_url, "{}/preinferences".format(str(task['id'])))
res = requests.post(preinference_url, json={'information': information}, headers=headers)
page = page + 1
if __name__ == '__main__':
main()