- 概要
- スタートアップガイド
- ユーザガイド
-
リファレンス
-
ABEJA Platform CLI
- CONFIG COMMAND
- DATALAKE COMMAND
- DATASET COMMAND
- TRAINING COMMAND
-
MODEL COMMAND
- check-endpoint-image
- check-endpoint-json
- create-deployment
- create-endpoint
- create-model
- create-service
- create-trigger
- create-version
- delete-deployment
- delete-endpoint
- delete-model
- delete-service
- delete-version
- describe-deployments
- describe-endpoints
- describe-models
- describe-service-logs
- describe-services
- describe-versions
- download-versions
- run-local
- run-local-server
- start-service
- stop-service
- submit-run
- update-endpoint
- startapp command
- SECRET COMMAND
- SECRET VERSION COMMAND
-
ABEJA Platform CLI
- FAQ
- Appendix
トリガー機能
はじめに
このドキュメントでは、「トリガー」機能について解説します。
トリガー機能とは
特定の動作実行時に、作成した推論APIを実行し、推論結果を出力する機能となります。
入力サービスタイプ (トリガー発動動作)
- DataLake
- スケジュール
出力サービスタイプ
- DataLake
トリガー作成手順
左メニューから「デプロイメント」の「サービス」を選択後、「トリガー」タブを選択し、「トリガー作成」を選択します。 トリガー実行時に利用する「コード」、「モデル」、「バージョン」を指定後、入力サービスを指定します。
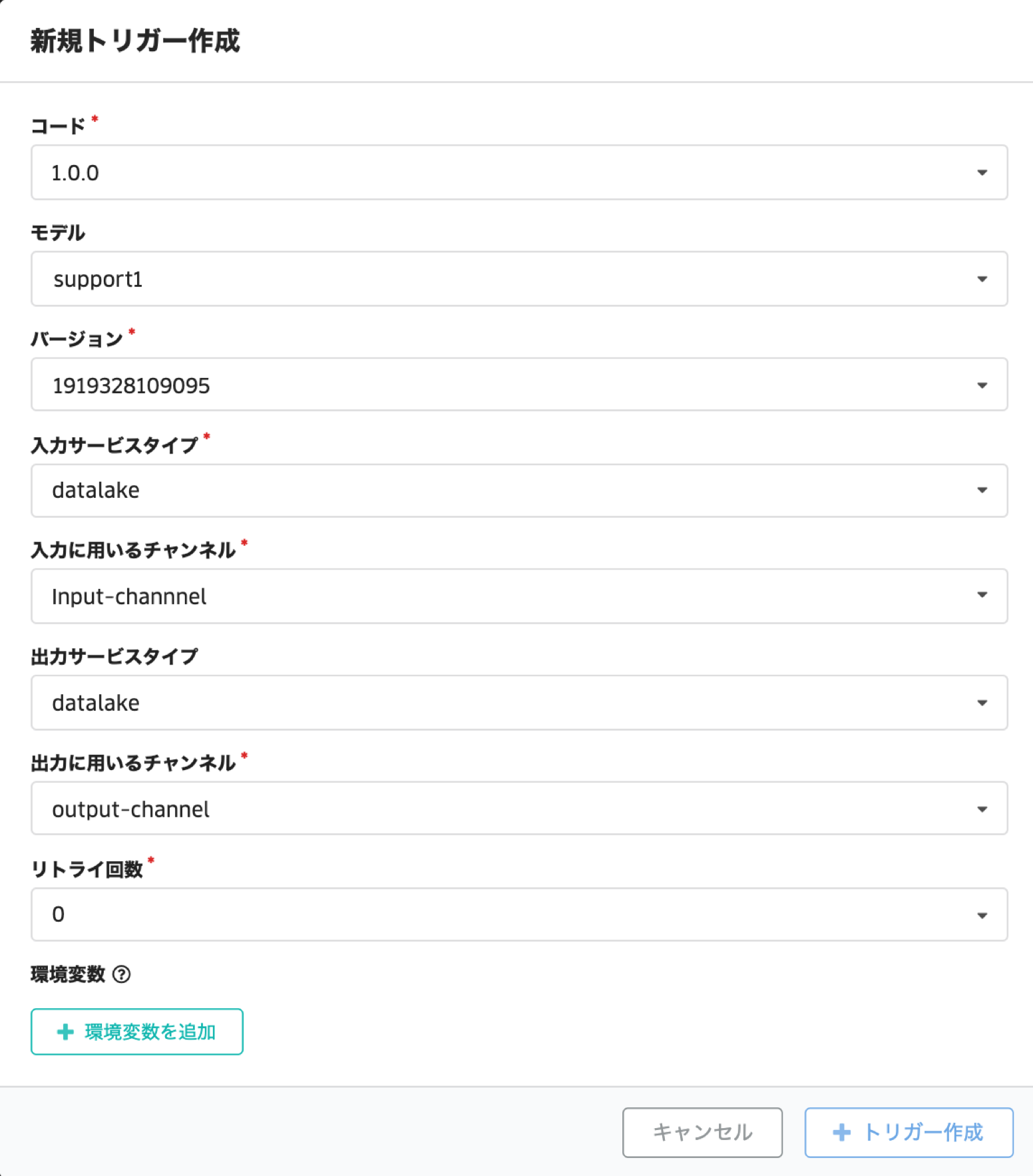
入力サービスを「datalake」に指定した場合
入力サービスに「datalake」を指定した場合、DataLakeのチャンネルを指定します。
入力サービスを「schedule」に指定した場合
「入力のスケジュールルール」を記載する必要があります。 スケジュールルールの書式については、スケジュールの書式をご参考ください。 指定スケジュールは標準ではUTCとなっているため、タイムゾーンを指定します。
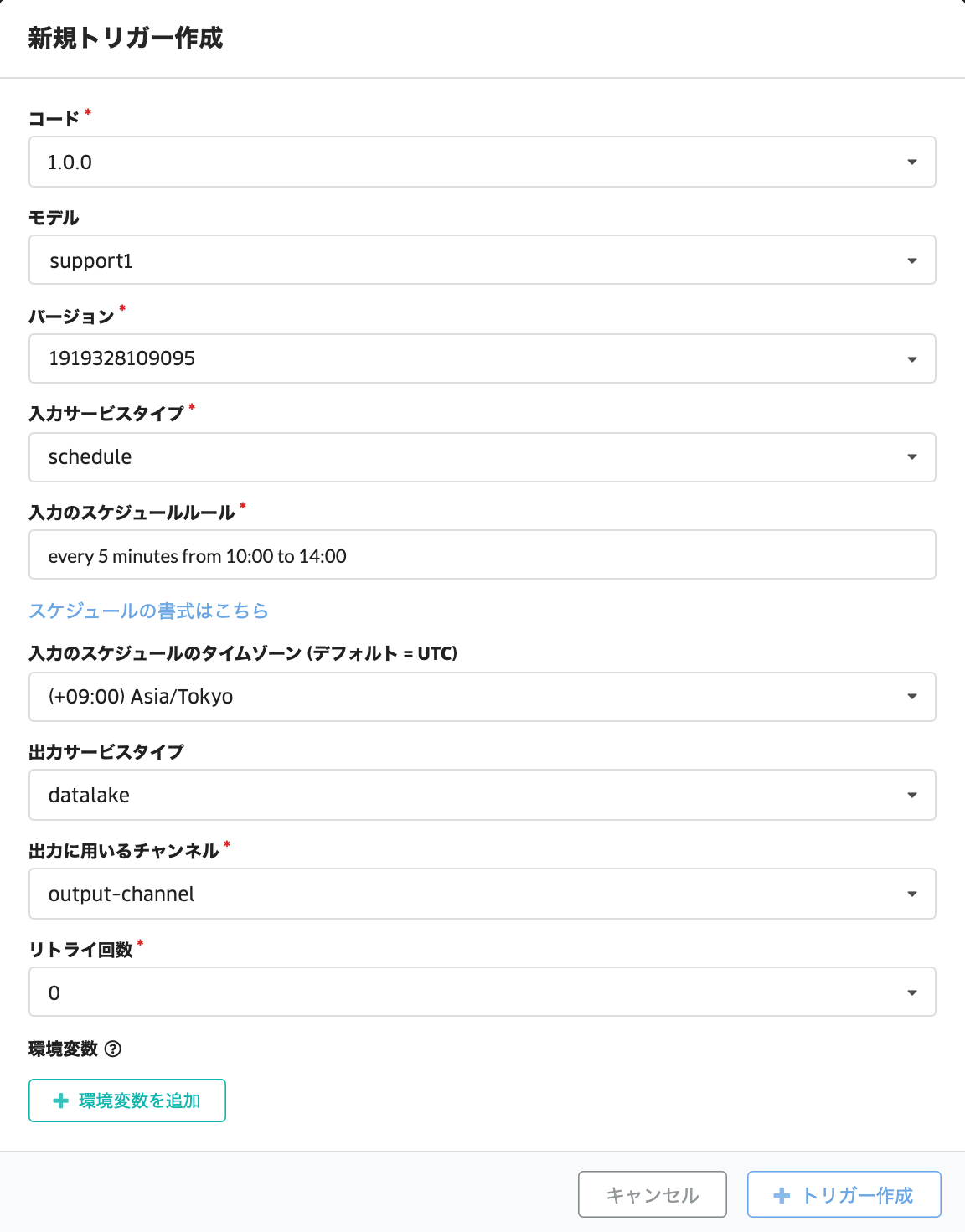
出力サービスタイプについては、「datalake」となります。 「出力に用いるチャンネル」に出力結果(推論結果)を格納するためのチャンネルを指定します。
「リトライ回数」は実行が失敗した場合に、リトライする回数を指定します。
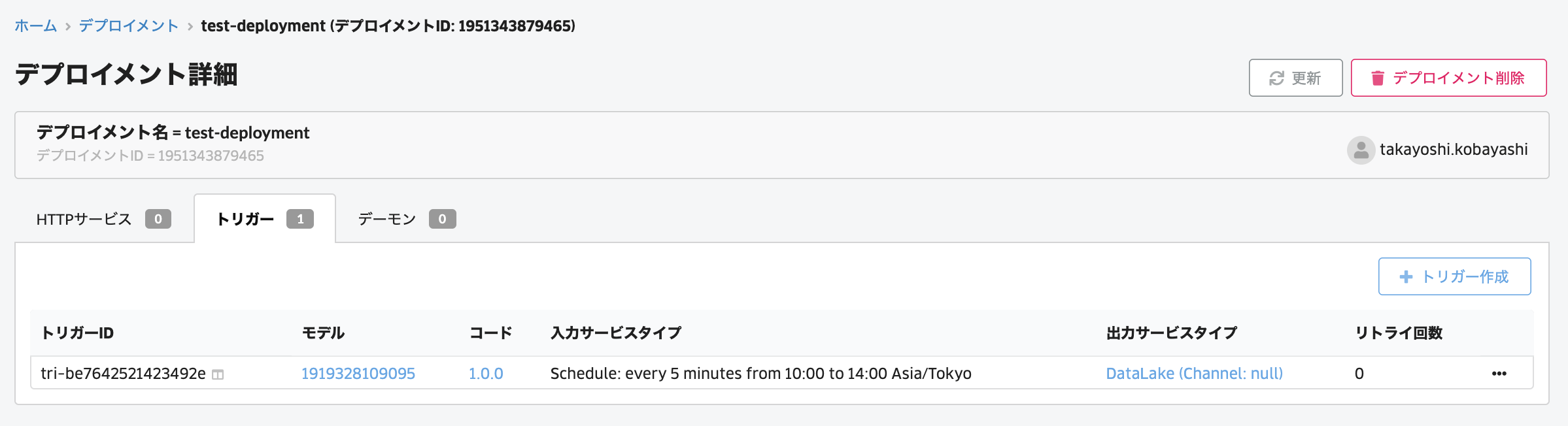
作成ができましたら、DataLake、もしくはスケジュールで指定した時間に推論結果がJSON形式で出力サービスタイプで指定したDataLakeチャンネルに保管されます。