- 概要
- スタートアップガイド
- ユーザガイド
-
リファレンス
-
ABEJA Platform CLI
- CONFIG COMMAND
- DATALAKE COMMAND
- DATASET COMMAND
- TRAINING COMMAND
-
MODEL COMMAND
- check-endpoint-image
- check-endpoint-json
- create-deployment
- create-endpoint
- create-model
- create-service
- create-trigger
- create-version
- delete-deployment
- delete-endpoint
- delete-model
- delete-service
- delete-version
- describe-deployments
- describe-endpoints
- describe-models
- describe-service-logs
- describe-services
- describe-versions
- download-versions
- run-local
- run-local-server
- start-service
- stop-service
- submit-run
- update-endpoint
- startapp command
- SECRET COMMAND
- SECRET VERSION COMMAND
-
ABEJA Platform CLI
- FAQ
- Appendix
テンプレート学習 (Object Detection)
はじめに
このドキュメントでは、ABEJA Templateを利用して、Object Detectionのモデル作成をノンコーディングで実施する方法を解説します。
前提
このマニュアルでは、Object Detectionのデータセットを利用します。以下を参考に Object Detection のデータセットを用意ください。
■サンプルデータセットを作成する
サンプルとして、こちらのスクリプトを利用し、 PASCAL VOC サンプルのデータセットを作成することも可能です。 (アノテーションデータ付きの画像データセットとなります。)
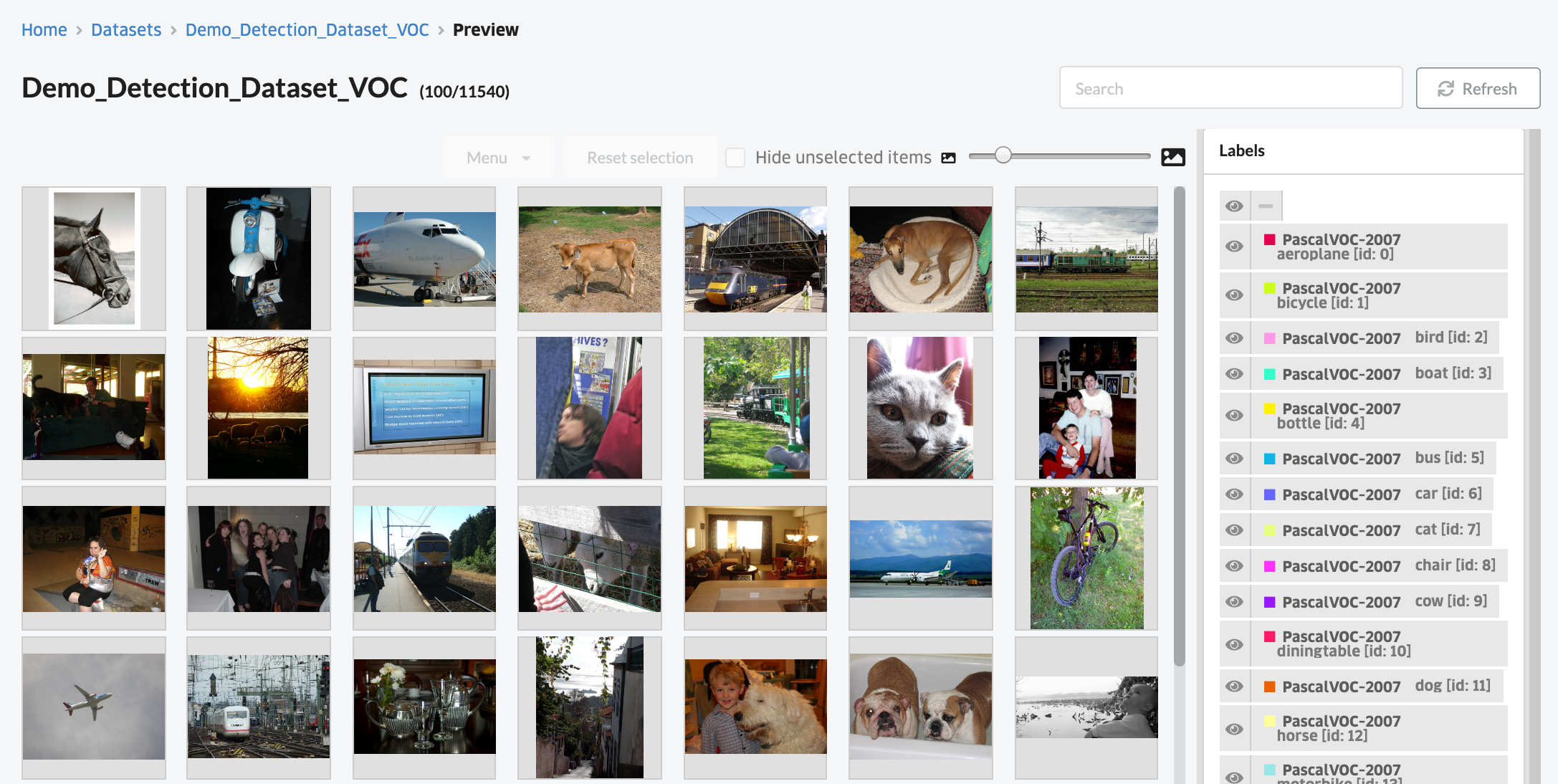
■データレイクへファイルをアップロードし、アノテーションツールを使ってデータセットを作成する
■アノテーション済みのデータを既にお持ちの場合
データセット(教師データ)を元にABEJA Templateを利用して機械学習モデルを作成する
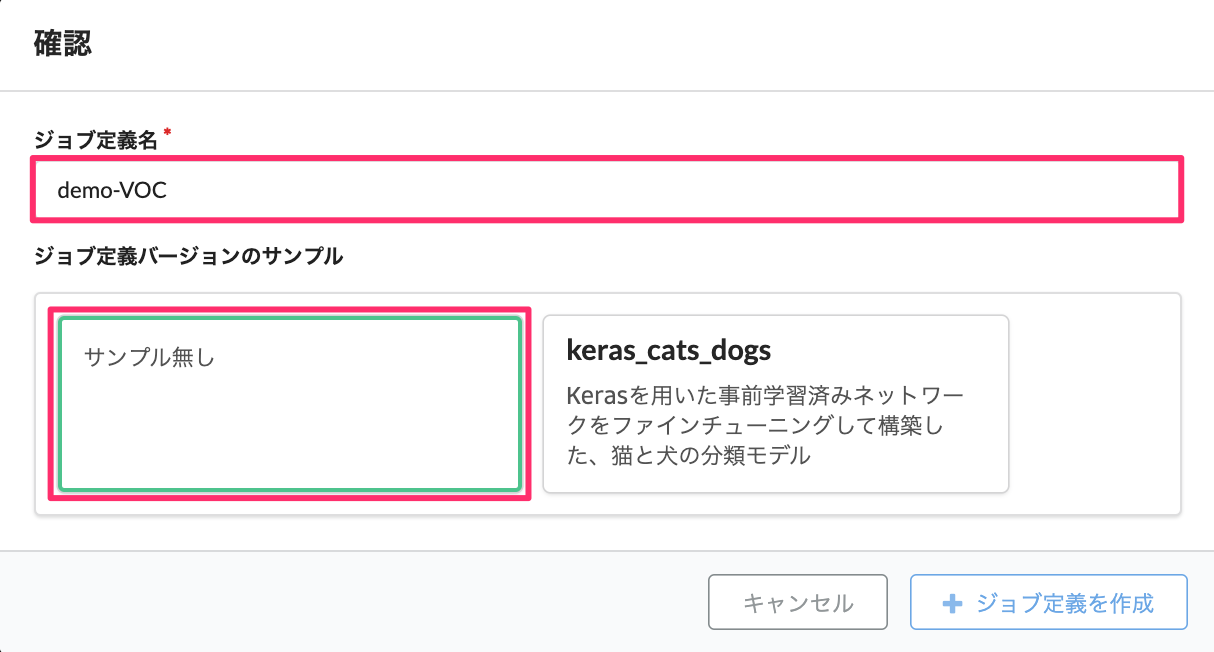
まずは、コンソールの 「学習」 の「ジョブ定義」のページから、ジョブ定義を作成します。「サンプル無し」を選択します。
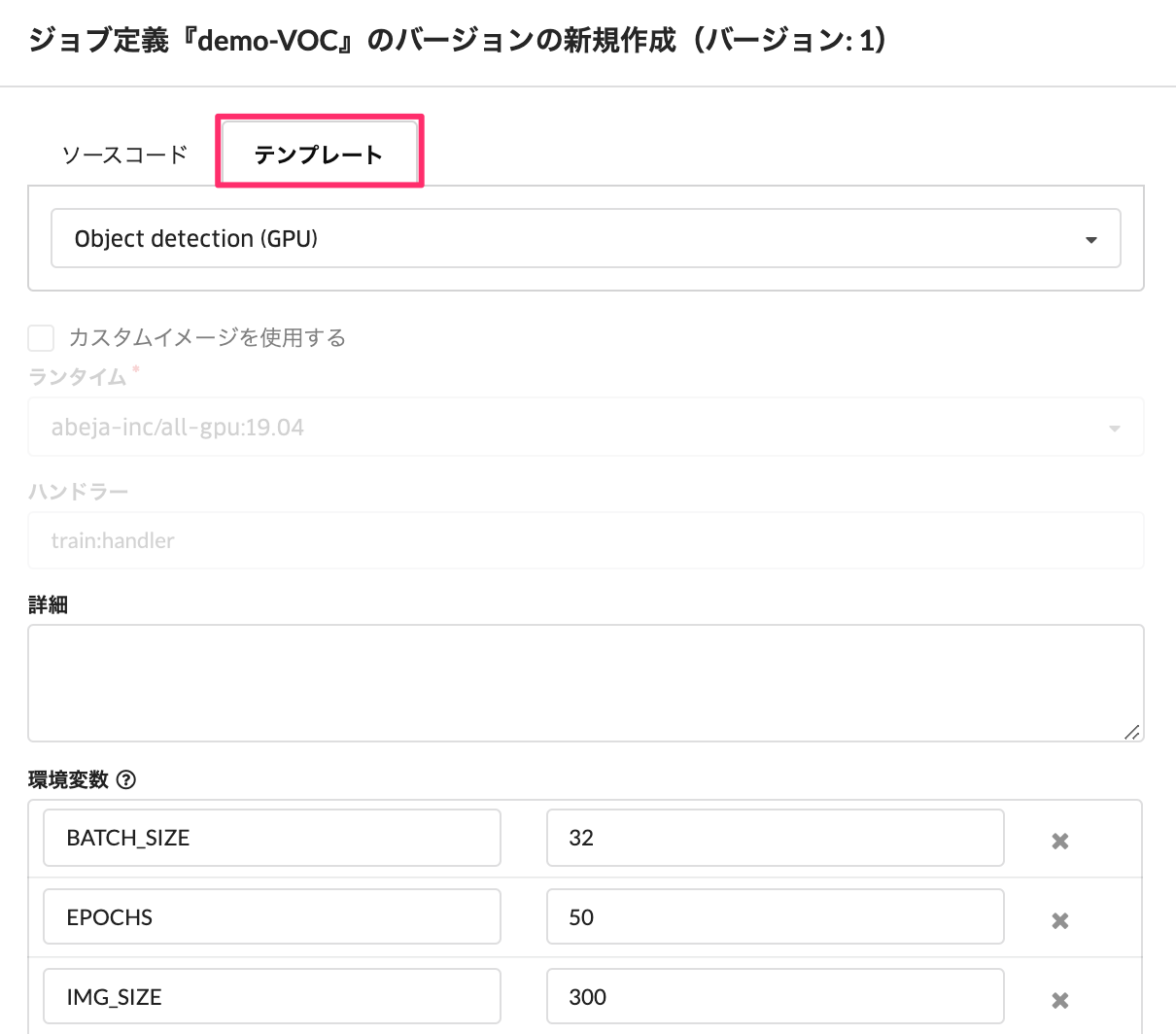
その後、バージョンを作成します。「バージョン作成」を選択後、タブの「テンプレート」をクリックして、Object DetectionのCPUまたはGPUを選択します。 この例では GPU を選択します。また、このページでも環境変数(各種ハイパーパラメータ)を調整可能です。 各種ハイパーパラメータ情報の説明については、こちらを参考ください。

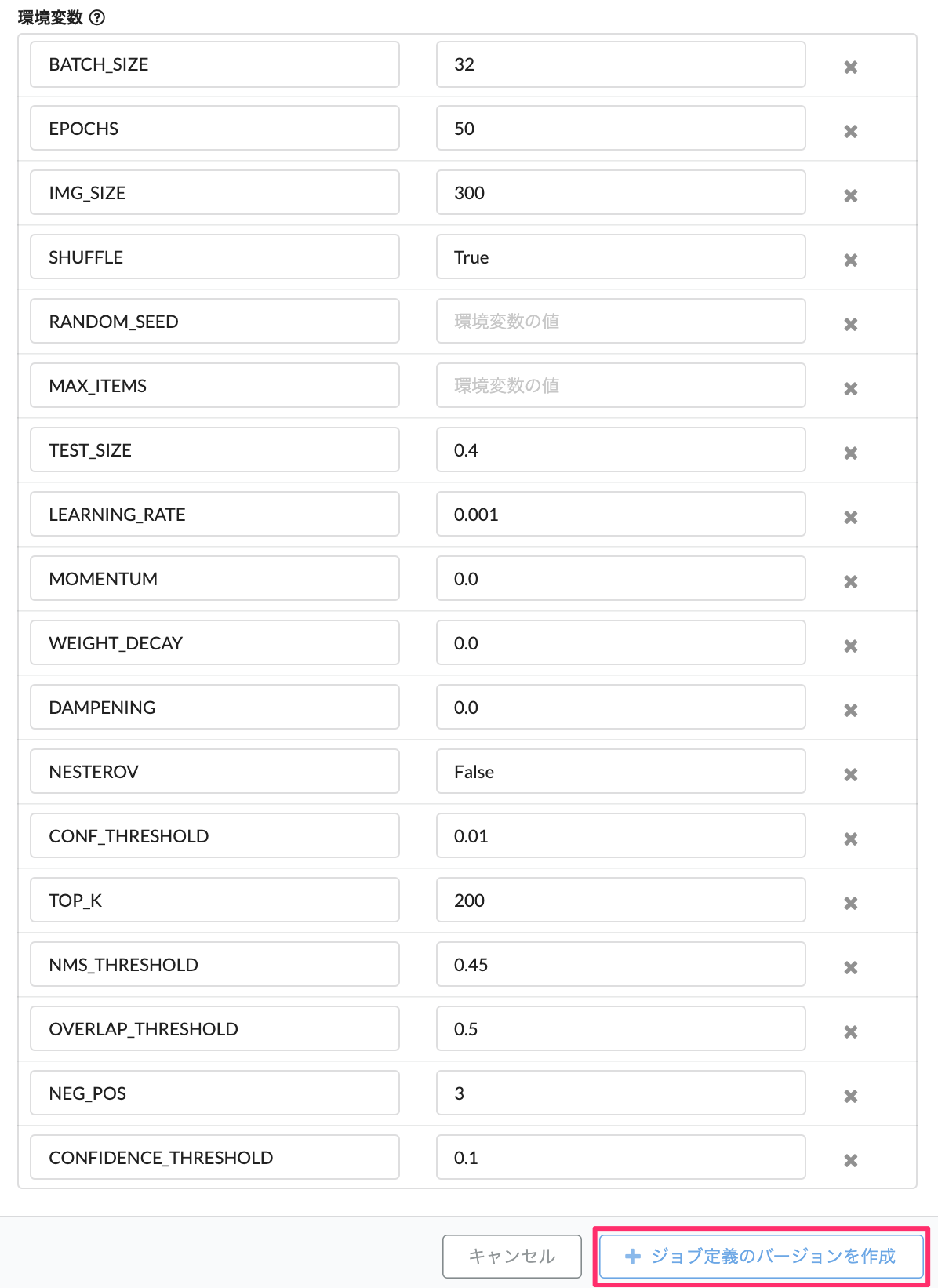
ジョブ定義に「ジョブのバージョン」が作成されました。
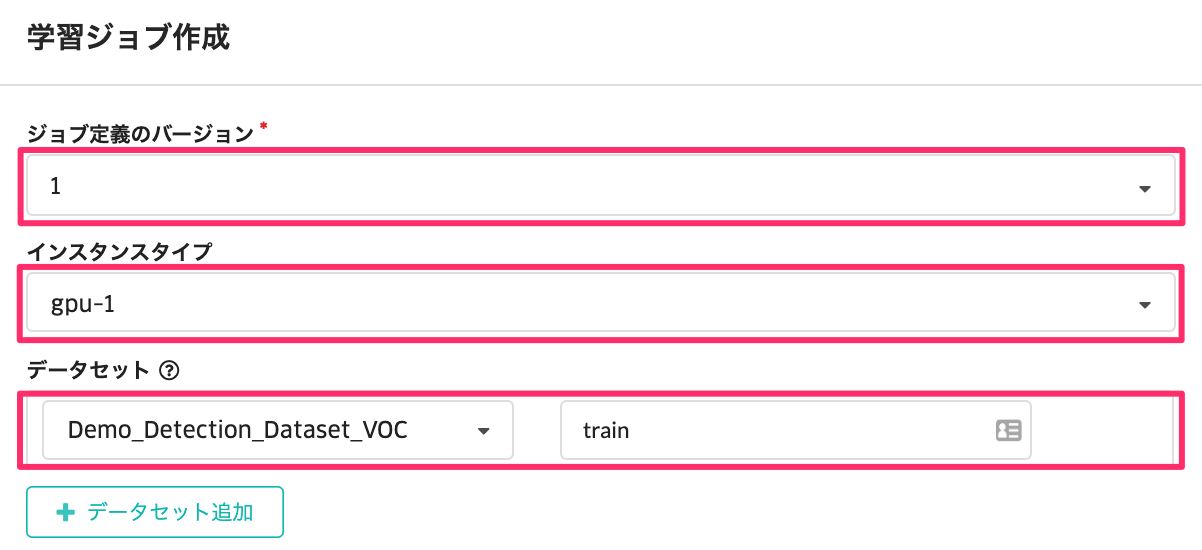
続いて、「ジョブ」をクリックして、学習ジョブを作成します。


この画面では以下の項目を設定します。
| 項目 | 説明 |
|---|---|
| ジョブ定義のバージョン | 学習に利用するバージョンを選択 |
| インスタンスタイプ | 各インスタンスタイプを選択 (※今回はgpu-1を選択) |
| データセット | モデルに学習させるデータセット名を指定。エイリアスには、 train や Val と入力 |
| 環境変数 | ジョブのバージョンで定義された各種パラメータを表示、各項目を右側の編集ボタンを選択することで調整可能 |
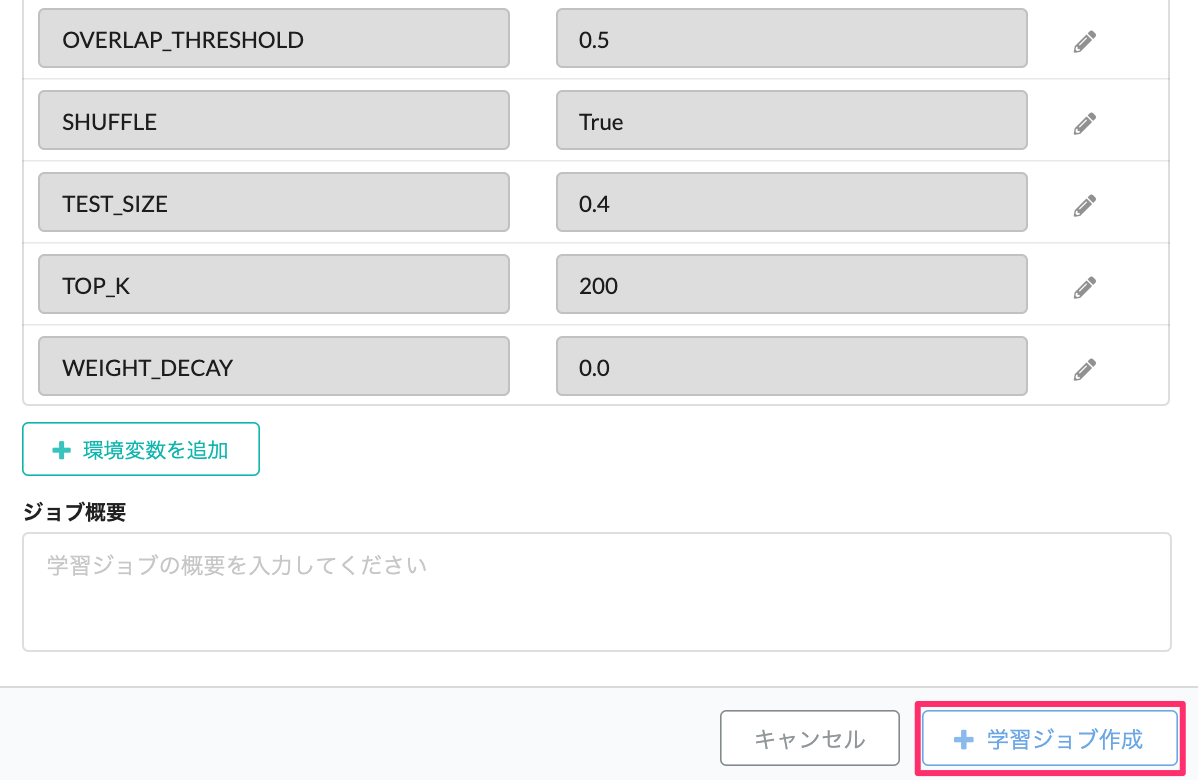
最後に、学習ジョブ作成を選択すると学習ジョブが実行されます。 学習ジョブが実行されました。各ジョブごとに設定されているパラメータやデータセットは画面上からも確認いただけます。
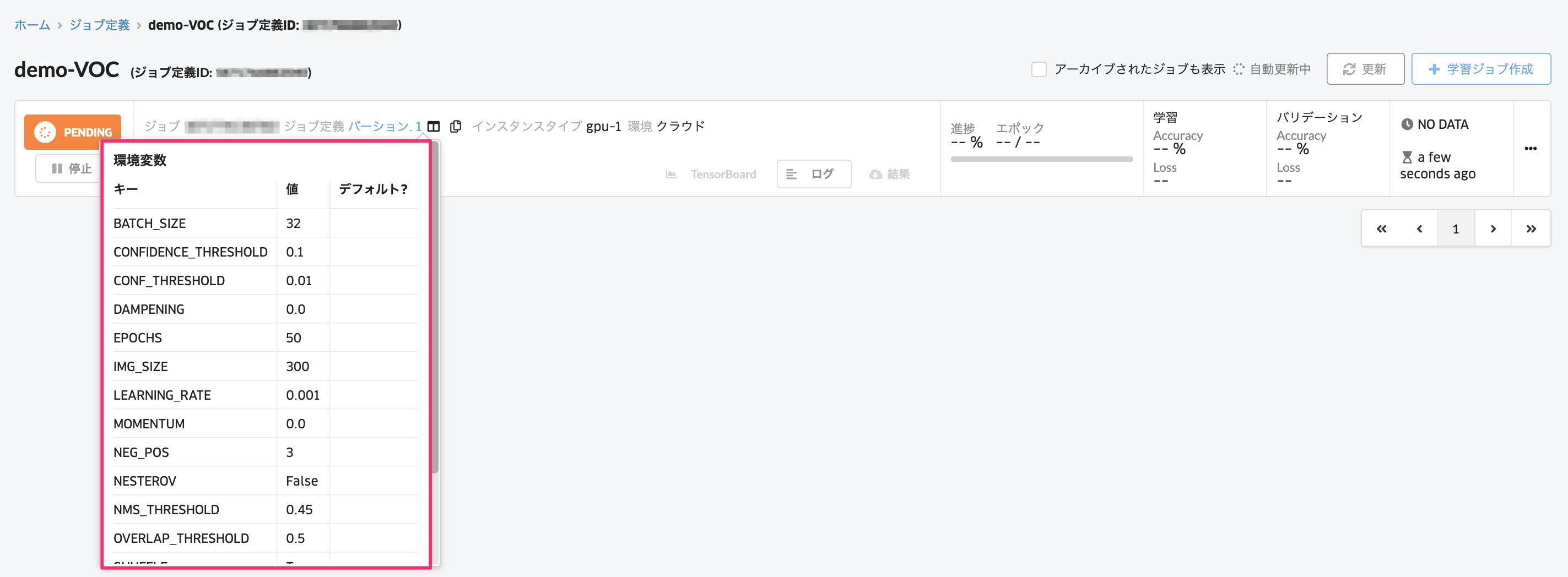

学習開始後にTensorBoardのボタンをクリックすると、TensorBoardの画面が開き、Training Loss, Validation Lossのデータを可視化できます。
管理画面上に学習の進捗が表示されているので、学習が終わるのを待ちます。
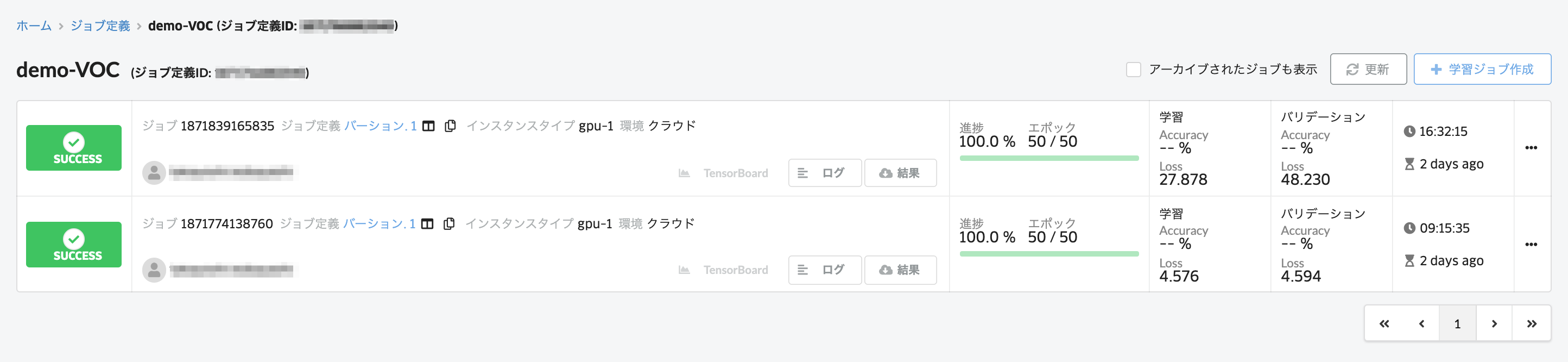
ここでは、ABEJA Templateを利用してノンコーディングでObject Detectionのモデル作成方法を解説しました。